Transformaciones de datos avanzadas
En este artículo, aprenderá cómo transformar datos en situaciones particulares, como cuando los datos con los que está trabajando están sesgados. Aprenderás:
- Cómo transformar datos sesgados
- ¿Qué es la transformación logarítmica y por qué es útil?
- Cómo implementar la transformación de registros en Python
- Diferentes tipos de transformaciones de datos avanzadas
Datos sesgados
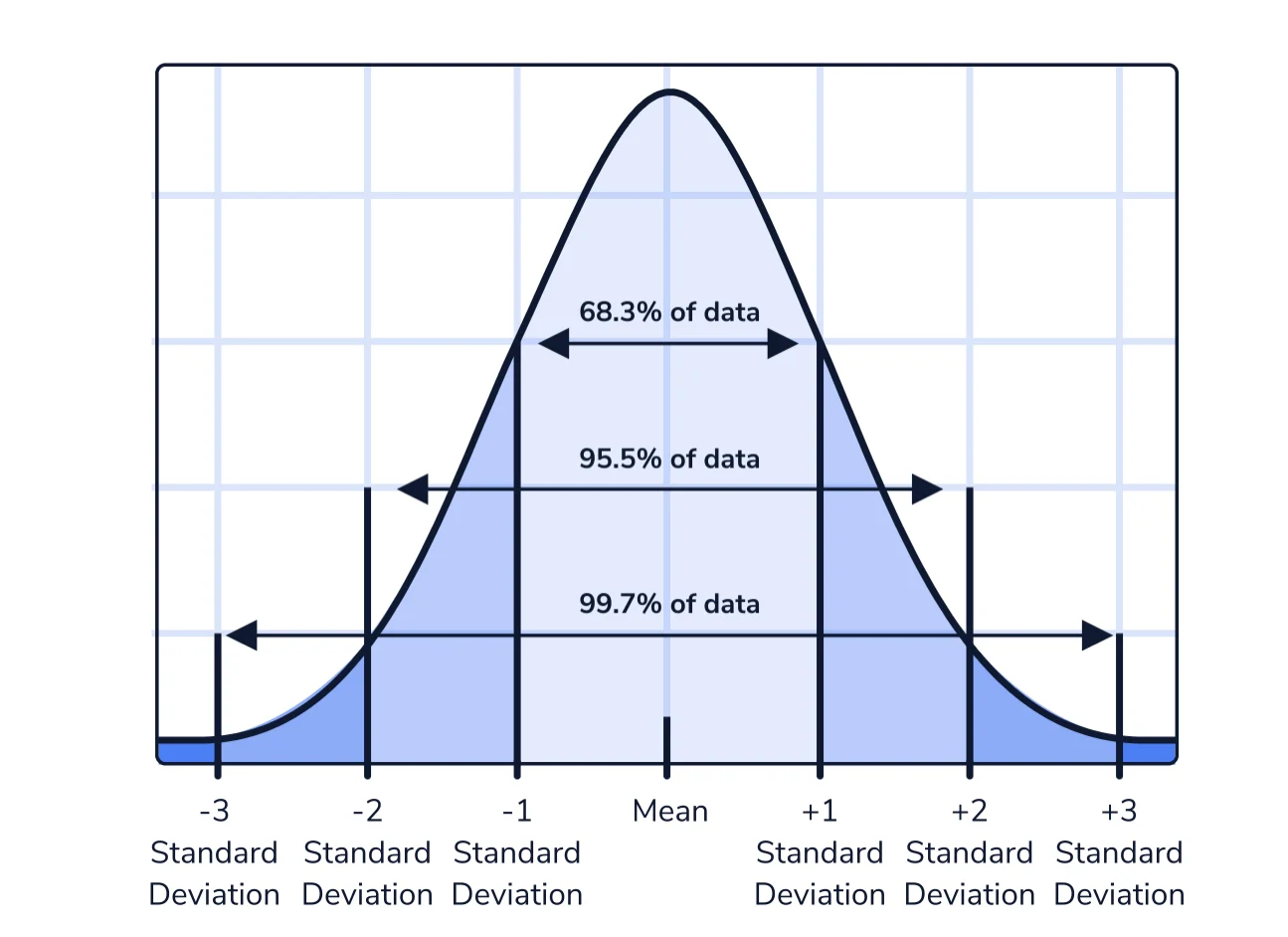
Como analista de datos y científico, a menudo trabajará con datos distribuidos normalmente. Solo como repaso, los datos distribuidos normalmente son datos en los que la mayoría de los puntos de datos están cerca de un valor central con menos instancias a medida que se aleja del centro. Visualmente, esto parece una “curva de campana”:
Hay varias razones por las que es útil tener datos distribuidos normalmente:
- Las distribuciones normales son simétricas alrededor de su media. Además, la media, la mediana y la moda de una distribución normal son iguales. Estas propiedades hacen que los datos sean más fáciles de analizar porque podemos hacer algunas suposiciones sobre cuántos puntos de datos hay a cada lado de la media.
- Como se muestra arriba, aproximadamente el 68 % de los datos se encuentran dentro de 1 desviación estándar de la media y aproximadamente el 95 % de los datos se encuentran dentro de 2 desviaciones estándar de la media. Nuevamente, estas propiedades facilitan la realización de generalizaciones sobre los datos con los que está trabajando.
- Muchos algoritmos de aprendizaje automático (como la regresión lineal) suponen que la distribución de los datos es cercana a la normal. Por lo tanto, transformar los datos para que se distribuyan normalmente puede mejorar su capacidad para ajustarse a un modelo predictivo preciso.
A menudo, los datos de la vida real son confusos y no se ajustan a una distribución normal. En cambio, los datos podrían estar sesgados hacia la izquierda o hacia la derecha.
Por ejemplo, imagine que es un analista de datos que analiza datos de ingresos de una población. Es posible que descubra que muchos de los datos se centran en valores más bajos, pero que también hay valores altos en los datos. Esto da como resultado una distribución sesgada:

Este es un ejemplo de un conjunto de datos sesgado a la derecha . Los ingresos más bajos, que constituyen la mayor parte de los datos, se encuentran en el lado izquierdo del diagrama, mientras que los ingresos más altos se encuentran en el lado derecho.
Alimentar estos datos con algunos modelos estadísticos o de aprendizaje automático presentará problemas si el modelo asume normalidad, porque el modelo se entrenará en un número mucho mayor de ingresos más bajos. La asimetría de los datos viola los supuestos del modelo.
En situaciones como esta, nos gustaría hacer que nuestros datos sean menos sesgados para que se ajusten a los supuestos del modelo y sea más fácil trabajar con ellos. Para ayudar con este problema, podemos usar Log Transformation .
Transformación de registros
La transformación de registros es un método de transformación de datos que reemplaza cada variable x con log(x).
Cuando se aplica la transformación de registros a datos que no están distribuidos normalmente, el resultado es que los datos serán menos sesgados o más “normales” que antes. Por ejemplo, después de aplicar la transformación logarítmica al conjunto de datos sesgado hacia la derecha anterior, veríamos algo similar a lo siguiente:
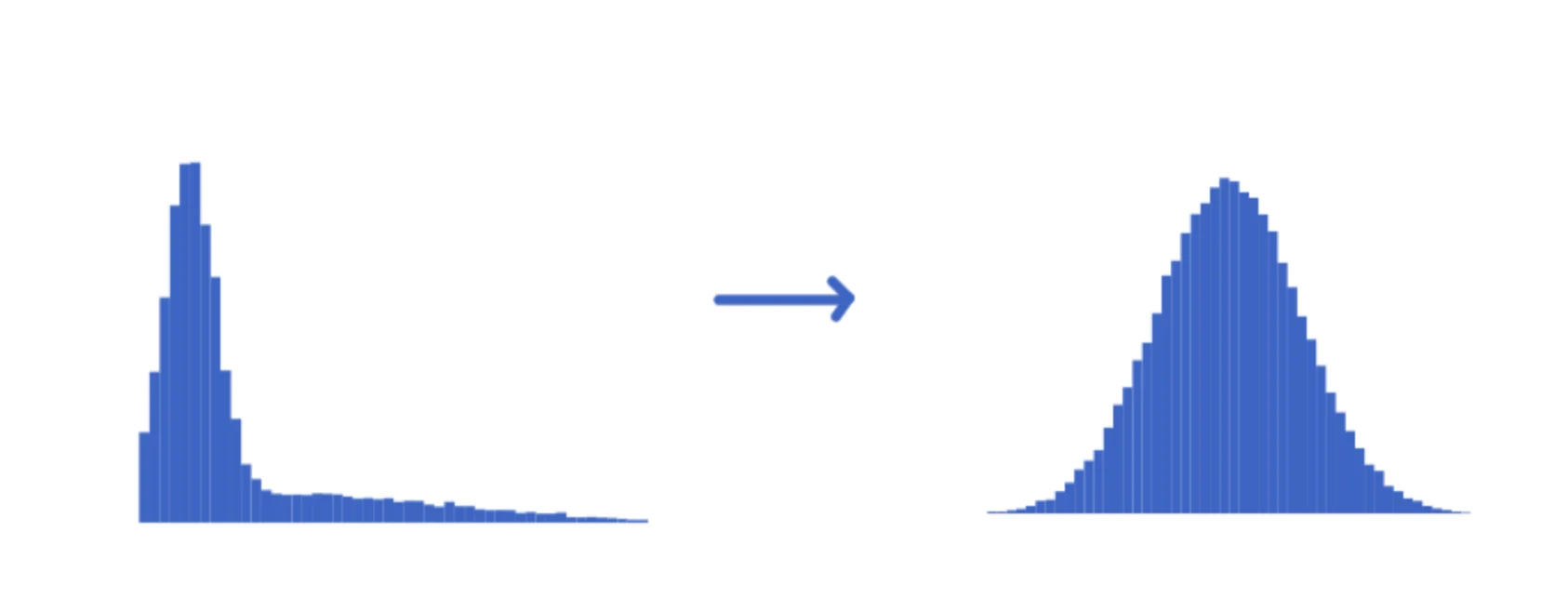
Observe cómo cambió la forma de los datos. La función logaritmo junta los valores más grandes de su conjunto de datos y extiende los valores más pequeños, haciendo que los datos transformados sean más “normales” que antes. Veamos cómo podemos aplicar esto a datos reales en Python.
Implementación en Python
Python contiene bibliotecas que simplifican la transformación de sus datos mediante la transformación de registros.
Un método rápido es utilizar NumPy, una biblioteca de Python que facilita trabajar con matrices de datos y realizar análisis estadísticos. Numpy tiene una función de transformación de registros naturales que puedes aplicar a una matriz de datos, así:
import numpy as np
data = [1, 1, 1, 1, 2, 2, 2, 3, 3, 4, 4]
# log transform
log_data = np.log(data)
print(log_data)
# 0, 0, 0, 0, 0.693, 0.693, 0.693, 1.098, 1.098, 1.386, 1.386
Los científicos de datos y los ingenieros de aprendizaje automático generalmente utilizarán potentes bibliotecas de aprendizaje automático, como scikit-learn para aplicar la transformación de registros. Puede importar PowerTransformer desde el módulo de sklearn preprocessing y luego pasar sus datos a una simple llamada de función:
from sklearn.preprocessing import PowerTransformer
# log transform
log_transform = PowerTransformer()
log_transform.fit_transform(data)
Intentemos realizar una transformación de registros en datos reales en Python. Trabajaremos con datos de precios de viviendas de Kaggle.
import numpy as np
import pandas as pd
import seaborn as sns
# read in data file
home_data = pd.read_csv('home_data.csv')
# store home price data
home_prices = home_data['SalePrice']
# plot data
sns.distplot(home_prices)
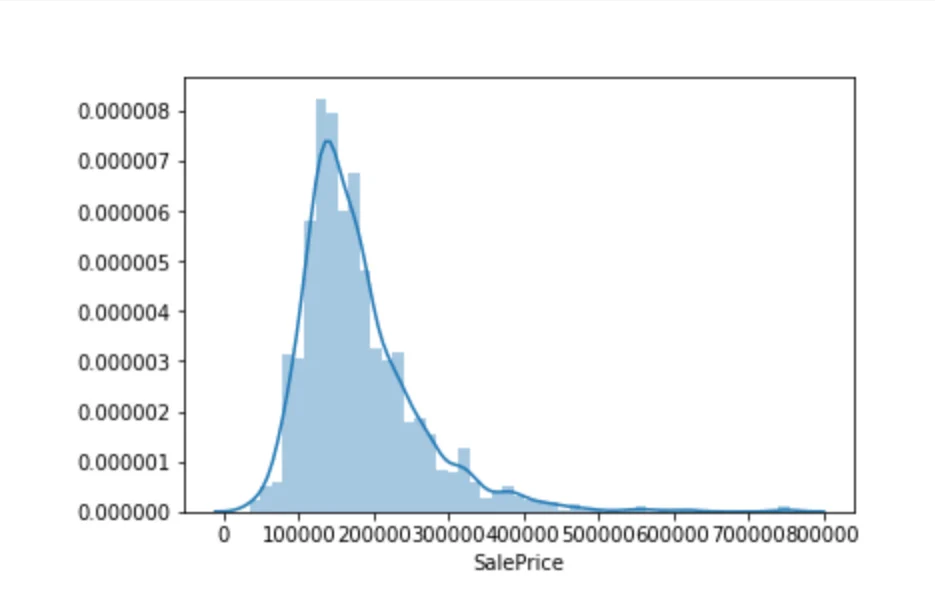
Lo primero que notamos es que nuestros datos están sesgados. La mayoría de nuestros datos consisten en precios de viviendas bajos y medios, mientras que los precios de viviendas más altos constituyen una pequeña parte de los datos. Veamos exactamente qué tan sesgados están nuestros datos:
print(home_prices.skew())
# 1.88
Generalmente, si la asimetría es menor que -1 o mayor que 1, la distribución está muy asimétrica. Nuestra distribución tiene una asimetría de 1,88, por lo que está muy asimétrica.
Si utilizáramos estos datos sesgados para predecir los precios de las viviendas, nos encontraríamos con algunos problemas. El modelo de predicción se entrenaría en un número mucho mayor de viviendas de precios bajos y moderados, por lo que tendría problemas para predecir los precios de las viviendas caras.
Para ayudar con esto, podemos aplicar la transformación de registros a nuestros datos:
import numpy as np
import pandas as pd
import seaborn as sns
home_data = pd.read_csv('home_data.csv')
home_prices = home_data['SalePrice']
sns.distplot(home_prices)
# apply log transformation
log_home_prices = np.log(home_prices)
# tracemos los datos transformados para ver la forma de la distribución:
sns.distplot(log_home_prices)
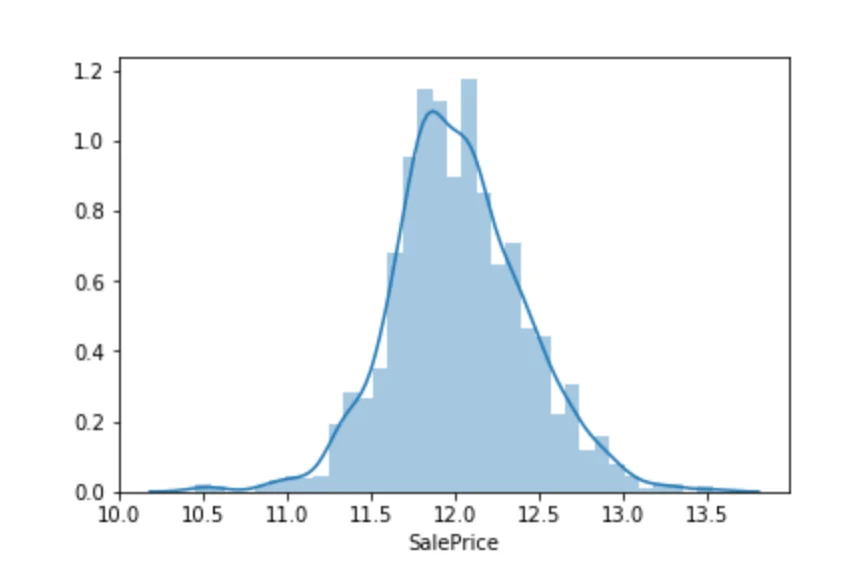
Observe cómo la forma de la distribución es mucho más simétrica (normal) que antes. Veamos qué tan sesgados están nuestros datos ahora:
print(home_prices.skew())
# 0.12133506220520406
La aplicación de la transformación logarítmica redujo la asimetría de 1,88 a 0,12: ¡es un cambio significativo!
Ahora que nuestros datos transformados están menos sesgados y tienen una distribución más normal, podemos utilizar estos datos en nuestro modelo de predicción para predecir con mayor precisión los precios de las viviendas.
Otras
En este artículo, analizamos solo un método avanzado de transformación de datos: la transformación de registros. Pero diferentes situaciones exigen otros tipos de transformaciones.
En los ejemplos anteriores, tratamos con datos de ingresos y precios, que no pueden ser negativos. Pero, ¿qué pasa si tienes números negativos en tus datos? No se puede tomar el registro de un número negativo, por lo que la transformación de registro no funcionará.
En este caso, tendría que explorar otras técnicas de transformación de datos, como la transformación de raíz cúbica , que implica convertir x en x^(1/3). Esta transformación reduce la asimetría correcta pero también tiene la ventaja de trabajar con valores cero y negativos.
Para reducir la asimetría hacia la izquierda, puede considerar una técnica como la transformación cuadrada , que implica convertir x en x^2.
Una parte importante de su trabajo como analista de datos y científico es comprender los datos con los que está trabajando y la forma de esos datos. Una vez que sepa esto, será más fácil descubrir cómo debe transformar esos datos.