Open Power System Data para comprender la TSA
En esta sección, utilizaremos Open Power System Data para comprender la TSA. Veremos las estructuras de datos de series de tiempo, la indexación basada en el tiempo y varias formas de visualizar datos de series de tiempo.
import pandas as pd
# load time series dataset
df = pd.read_csv("https://raw.githubusercontent.com/jenfly/opsd/master/opsd_germany_daily.csv")
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4383 entries, 0 to 4382
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 4383 non-null object
1 Consumption 4383 non-null float64
2 Wind 2920 non-null float64
3 Solar 2188 non-null float64
4 Wind+Solar 2187 non-null float64
dtypes: float64(4), object(1)
memory usage: 171.3+ KB
Las columnas del marco de datos se describen aquí :
Date: La fecha está en el formato yyyy-mm-dd.Consumption: Indica el consumo eléctrico en GWh.Wind: Indica la producción de energía eolica en GWh.Solar: Indica la producción de energía solar en GWh.Wind+Solar: Representa la suma de la producción de energía solar y eólica en GWh.
Data Transformation
Verificar los tipos de datos del conjunto de datos:
df.dtypes
Date object
Consumption float64
Wind float64
Solar float64
Wind+Solar float64
dtype: object
La Variable Date es de tipo Object y se debe convertir a formato DateTime
df['Date'] = pd.to_datetime(df['Date'])
# verificando
df.dtypes
Date datetime64[ns]
Consumption float64
Wind float64
Solar float64
Wind+Solar float64
dtype: object
Convertir Date en el Indice del Dataframe:
Utilizarás los valores de esta columna como índices de las filas en lugar de los índices numéricos predeterminados de Pandas.
df.set_index('Date', inplace=True)
df.tail(5)
| Consumption | Wind | Solar | Wind+Solar | |
|---|---|---|---|---|
| Date | ||||
| 2017-12-27 | 1263.94091 | 394.507 | 16.530 | 411.037 |
| 2017-12-28 | 1299.86398 | 506.424 | 14.162 | 520.586 |
| 2017-12-29 | 1295.08753 | 584.277 | 29.854 | 614.131 |
| 2017-12-30 | 1215.44897 | 721.247 | 7.467 | 728.714 |
| 2017-12-31 | 1107.11488 | 721.176 | 19.980 | 741.156 |
Agreguemos más columnas a nuestro marco de datos para faciltar el analisis. Agregemos Year, Month y Weekday Name:
df['Year'] = df.index.year
df['Month'] = df.index.month
df['Weekday Name'] = df.index.day_name()
df.sample(5)
| Consumption | Wind | Solar | Wind+Solar | Year | Month | Weekday Name | |
|---|---|---|---|---|---|---|---|
| Date | |||||||
| 2006-05-09 | 1353.229 | NaN | NaN | NaN | 2006 | 5 | Tuesday |
| 2007-01-09 | 1554.889 | NaN | NaN | NaN | 2007 | 1 | Tuesday |
| 2010-02-04 | 1521.671 | 82.257 | NaN | NaN | 2010 | 2 | Thursday |
| 2016-07-06 | 1413.597 | 430.530 | 182.117 | 612.647 | 2016 | 7 | Wednesday |
| 2016-01-25 | 1556.816 | 306.528 | 33.782 | 340.310 | 2016 | 1 | Monday |
Indexación basada en el tiempo
Tener una indexación basada en el tiempo permite utilizar una cadena formateada para seleccionar datos.
df.loc['2015-02-23']
Consumption 1592.656
Wind 365.763
Solar 28.046
Wind+Solar 393.809
Year 2015
Month 2
Weekday Name Monday
Name: 2015-02-23 00:00:00, dtype: object
df.loc['2017-01-01':'2017-12-30']
| Consumption | Wind | Solar | Wind+Solar | Year | Month | Weekday Name | |
|---|---|---|---|---|---|---|---|
| Date | |||||||
| 2017-01-01 | 1130.41300 | 307.125 | 35.291 | 342.416 | 2017 | 1 | Sunday |
| 2017-01-02 | 1441.05200 | 295.099 | 12.479 | 307.578 | 2017 | 1 | Monday |
| 2017-01-03 | 1529.99000 | 666.173 | 9.351 | 675.524 | 2017 | 1 | Tuesday |
| 2017-01-04 | 1553.08300 | 686.578 | 12.814 | 699.392 | 2017 | 1 | Wednesday |
| 2017-01-05 | 1547.23800 | 261.758 | 20.797 | 282.555 | 2017 | 1 | Thursday |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 2017-12-26 | 1130.11683 | 717.453 | 30.923 | 748.376 | 2017 | 12 | Tuesday |
| 2017-12-27 | 1263.94091 | 394.507 | 16.530 | 411.037 | 2017 | 12 | Wednesday |
| 2017-12-28 | 1299.86398 | 506.424 | 14.162 | 520.586 | 2017 | 12 | Thursday |
| 2017-12-29 | 1295.08753 | 584.277 | 29.854 | 614.131 | 2017 | 12 | Friday |
| 2017-12-30 | 1215.44897 | 721.247 | 7.467 | 728.714 | 2017 | 12 | Saturday |
364 rows × 7 columns
Visualizacion de Series Temporales
import matplotlib.pyplot as plt
import seaborn as sns
Configurar el tamaño y la resolución de las figuras generadas en los gráficos.
sns.set(rc={'figure.figsize':(11, 3)})
plt.rcParams['figure.figsize'] = (11,3)
plt.rcParams['figure.dpi'] = 150
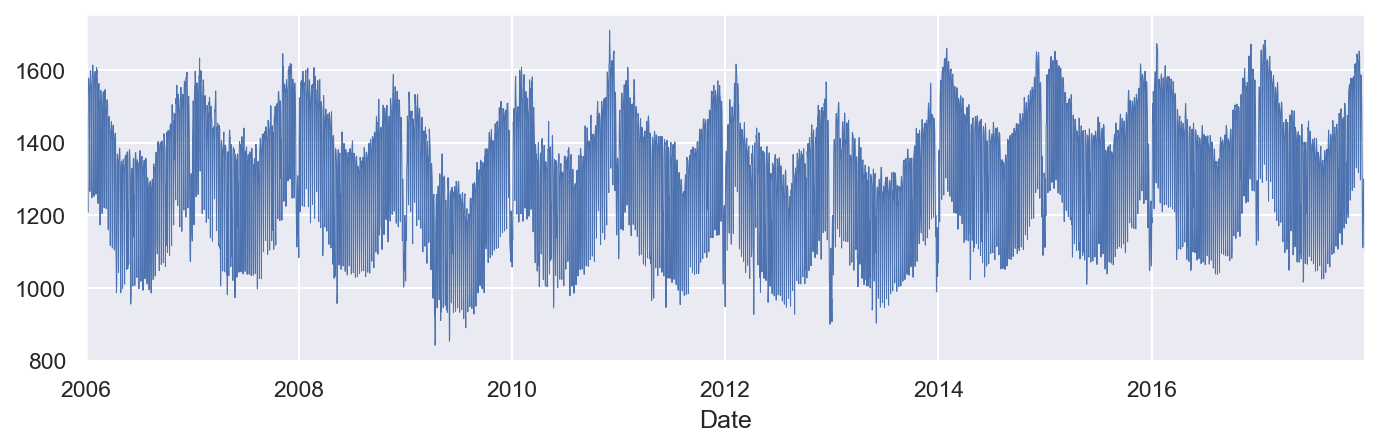
Gráfico lineal de la serie temporal completa del consumo eléctrico diario
El eje y muestra el consumo de electricidad y el eje x muestra el año. Sin embargo, hay demasiados conjuntos de datos para cubrir todos los años.
df['Consumption'].plot(linewidth=0.5)
<Axes: xlabel='Date'>
Usemos los puntos para trazar los datos de todas las demás columnas:
cols_to_plot = ['Consumption', 'Solar', 'Wind']
axes = df[cols_to_plot].plot(marker='.', alpha=0.5, linestyle='None',figsize=(14, 6), subplots=True)
for ax in axes:
ax.set_ylabel('Daily Totals (GWh)')
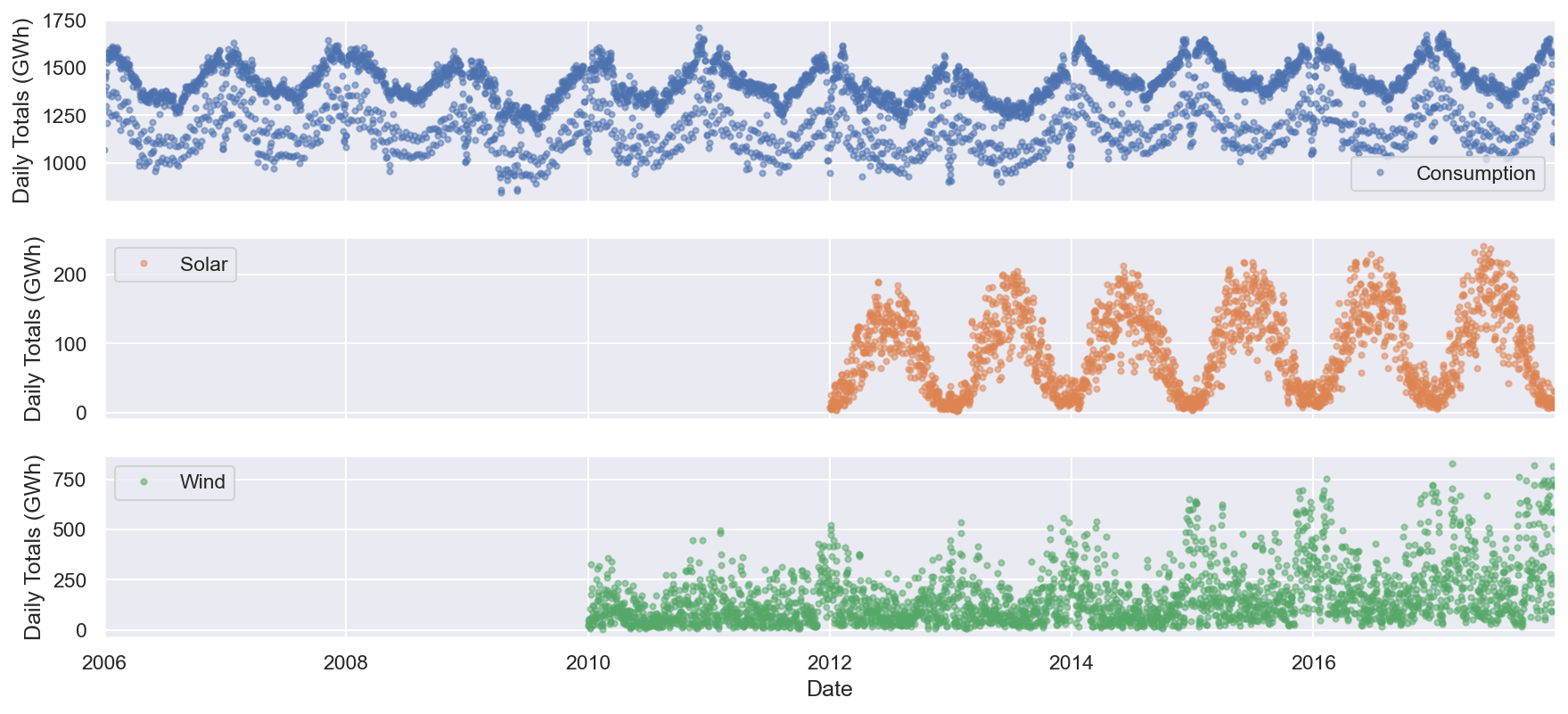
El resultado muestra que el consumo de electricidad se puede dividir en dos patrones distintos:
- Un grupo de aproximadamente 1.400 GWh y más
- Otro grupo aproximadamente por debajo de los 1.400 GWh
Podemos investigar más a fondo un solo año para verlo más de cerca. Verifique el código proporcionado aquí :
ax = df.loc['2016', 'Consumption'].plot()
ax.set_ylabel('Daily Consumption (GWh)');
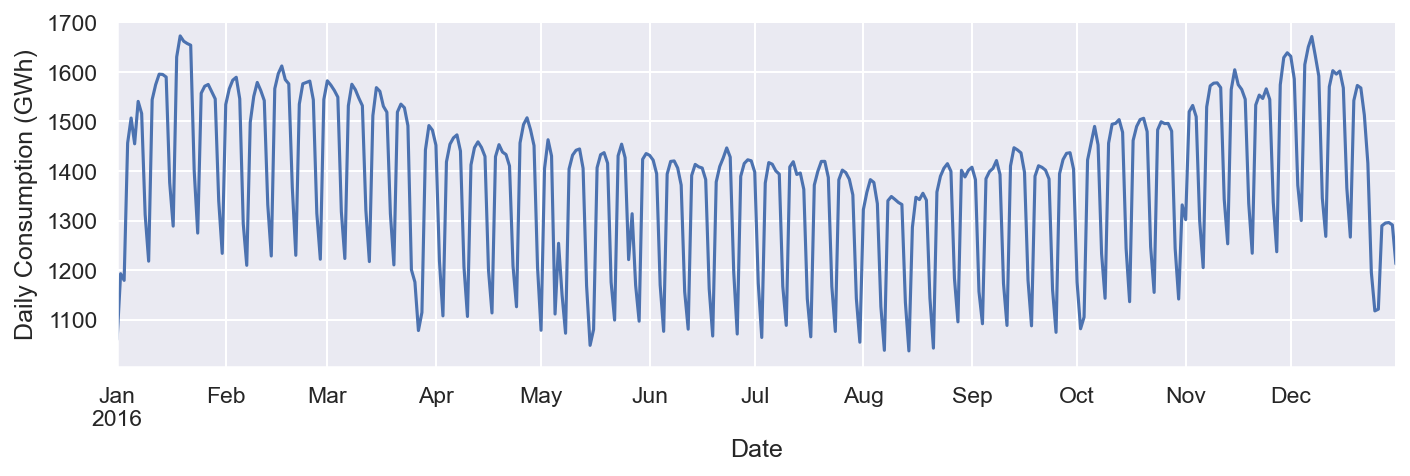
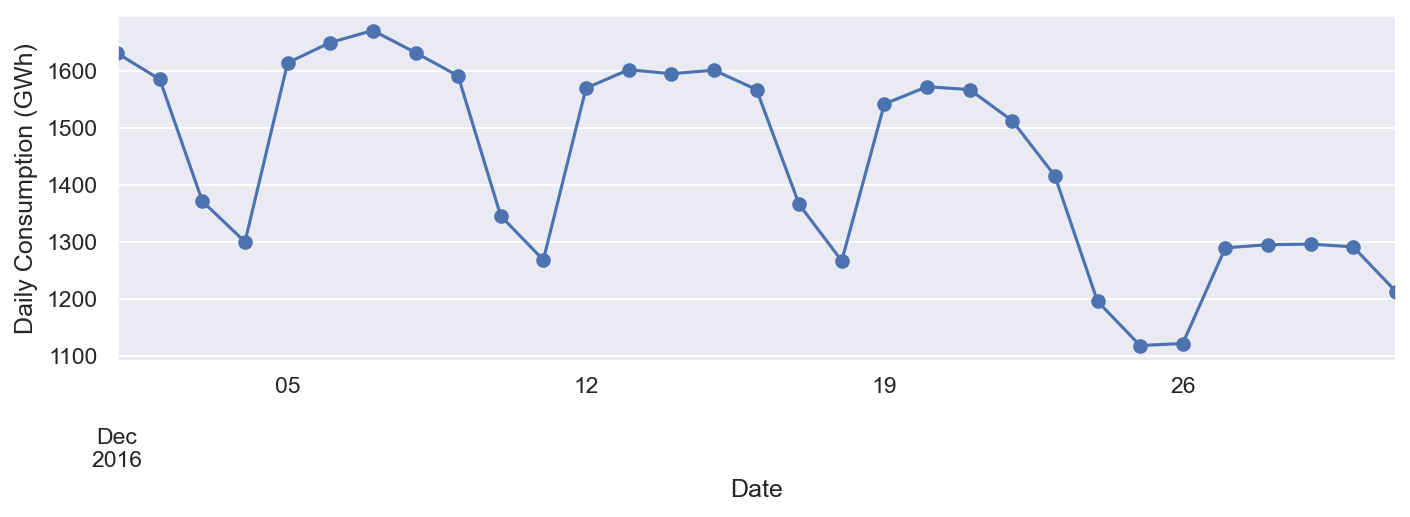
Podemos ver claramente el consumo de electricidad para 2016. El gráfico muestra una disminución drástica en el consumo de electricidad a finales de año (diciembre) y durante agosto. Podemos buscar más detalles en cualquier mes en particular. Examinemos el mes de diciembre de 2016 con el siguiente bloque de código:
ax = df.loc['2016-12', 'Consumption'].plot(marker='o', linestyle='-')
ax.set_ylabel('Daily Consumption (GWh)');
Como se muestra en el gráfico anterior , el consumo de electricidad es mayor entre semana y menor los fines de semana. Podemos ver el consumo de cada día del mes. Podemos acercarnos más para ver cómo se desarrolla el consumo en la última semana de diciembre.
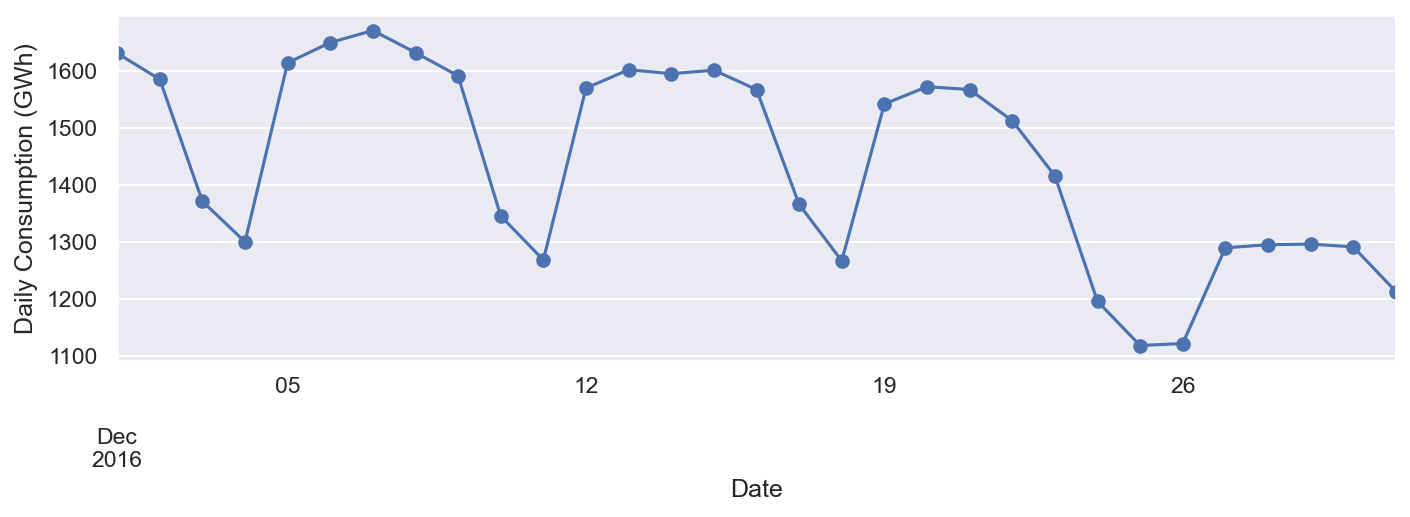
Para indicar una semana particular de diciembre, podemos proporcionar un rango de fechas específico como se muestra aquí :
ax = df.loc['2016-12-23':'2016-12-30', 'Consumption'].plot(marker='o', linestyle='-')
ax.set_ylabel('Daily Consumption (GWh)');
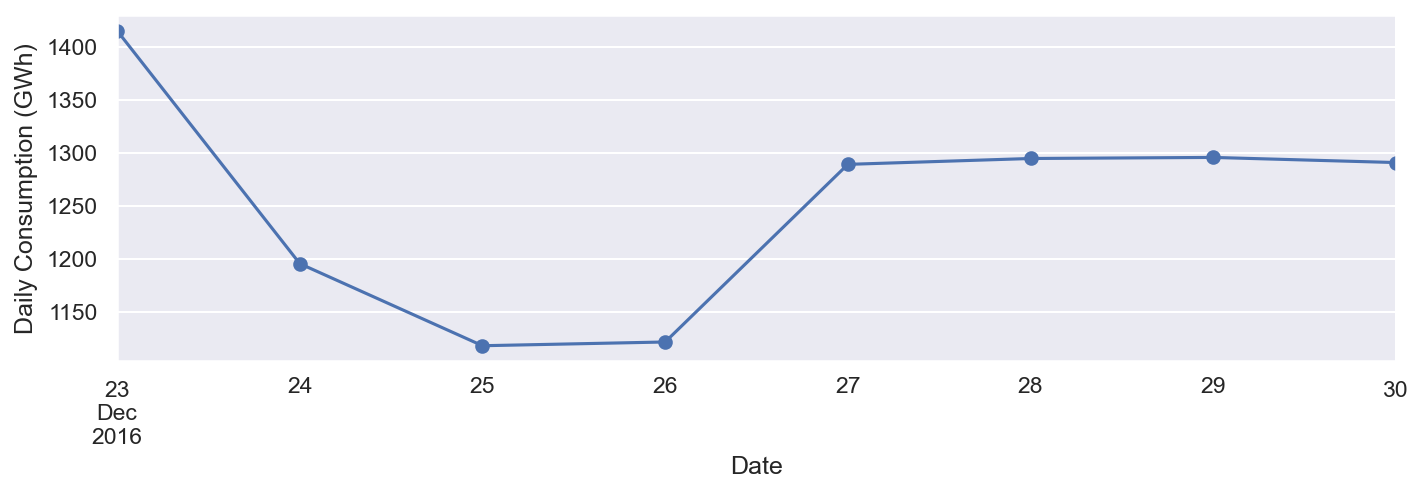
Como se ilustra en la captura de pantalla anterior, el consumo de electricidad fue más bajo el día de Navidad, probablemente porque la gente estaba ocupada de fiesta. Después de Navidad, el consumo aumentó.
ax = df.loc['2016-12', 'Consumption'].plot(marker='o', linestyle='-')
ax.set_ylabel('Daily Consumption (GWh)');
# import dates module from matplotlib
import matplotlib.dates as mdates
# plot graph
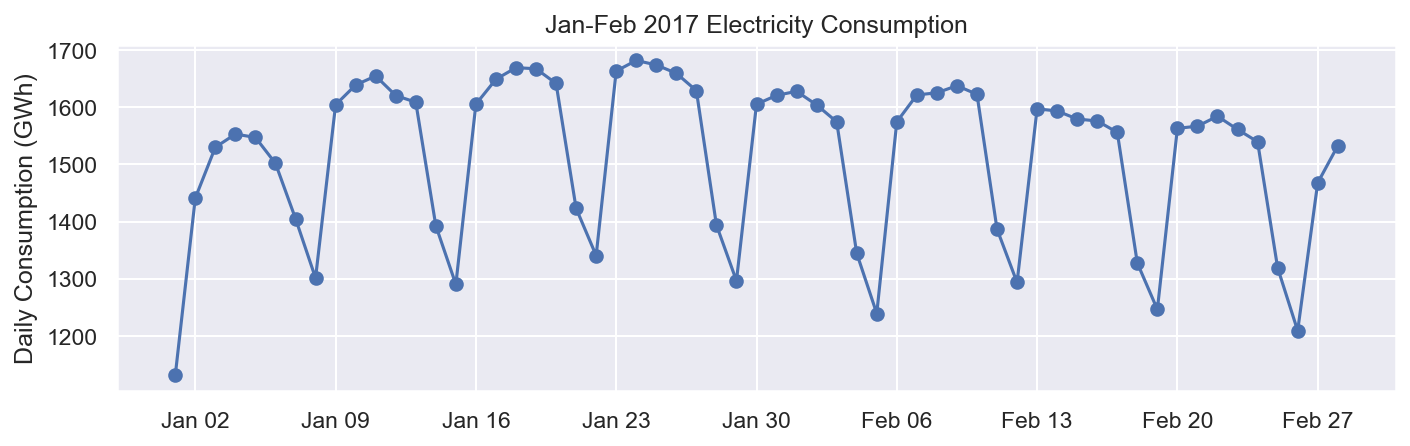
fig, ax = plt.subplots()
ax.plot(df.loc['2017-01':'2017-02', 'Consumption'], marker='o', linestyle='-')
ax.set_ylabel('Daily Consumption (GWh)')
ax.set_title('Jan-Feb 2017 Electricity Consumption')
# to set x-axis major ticks to weekly interval, on Mondays
ax.xaxis.set_major_locator(mdates.WeekdayLocator(byweekday=mdates.MONDAY))
# to set format for x-tick labels as 3-letter month name and day number
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b %d'));
Grouping time series data
Podemos agrupar los datos por diferentes períodos de tiempo y presentarlos en diagramas de caja. Primero podemos agrupar los datos por meses y luego usar los diagramas de caja para visualizar los datos:
fig, axes = plt.subplots(3, 1, figsize=(8, 7), sharex=True)
for name, ax in zip(['Consumption', 'Solar', 'Wind'], axes):
sns.boxplot(data=df, x='Month', y=name, ax=ax)
ax.set_ylabel('GWh')
ax.set_title(name)
if ax != axes[-1]:
ax.set_xlabel('')
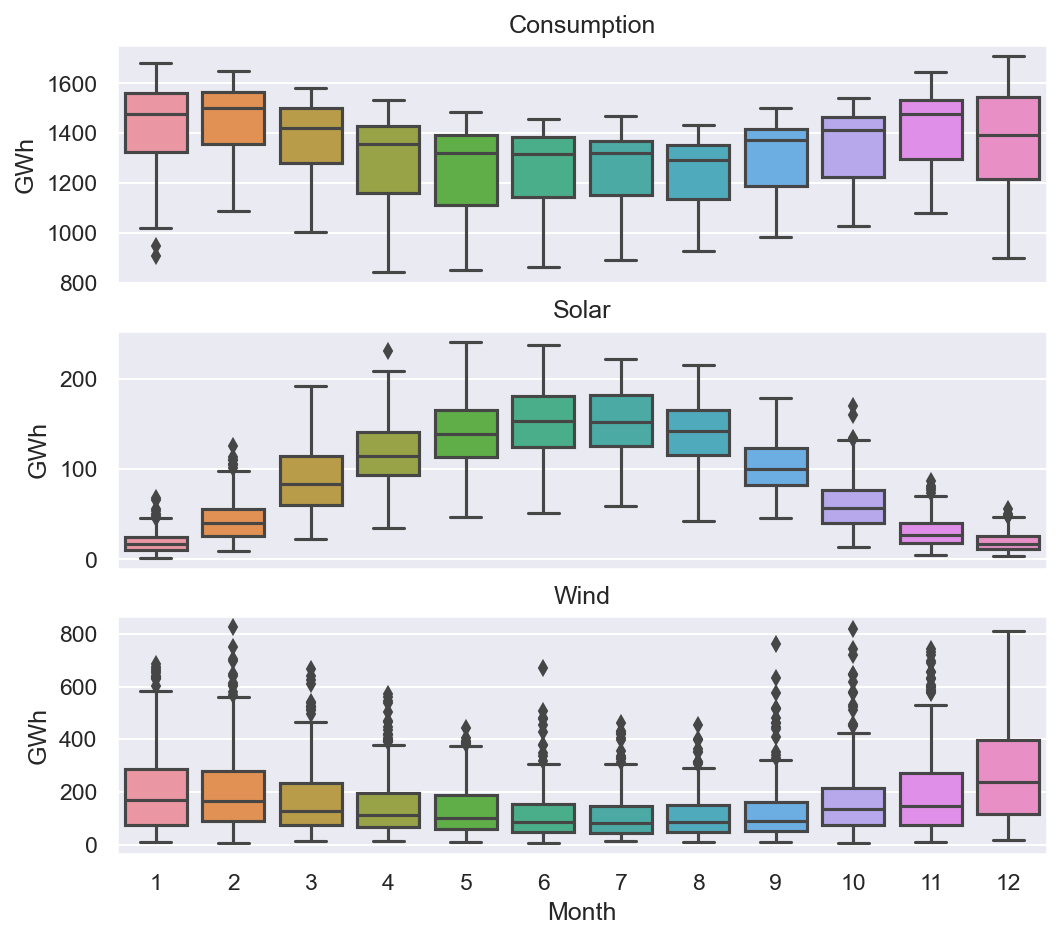
El gráfico anterior ilustra que el consumo de electricidad es generalmente mayor en invierno y menor en verano. La producción eólica es mayor durante el verano. Además, existen muchos valores atípicos asociados con el consumo de electricidad, la producción eólica y la producción solar.
Podemos agrupar el consumo de electricidad por día de la semana y presentarlo en un diagrama de caja:
sns.boxplot(data=df, x='Weekday Name', y='Consumption');
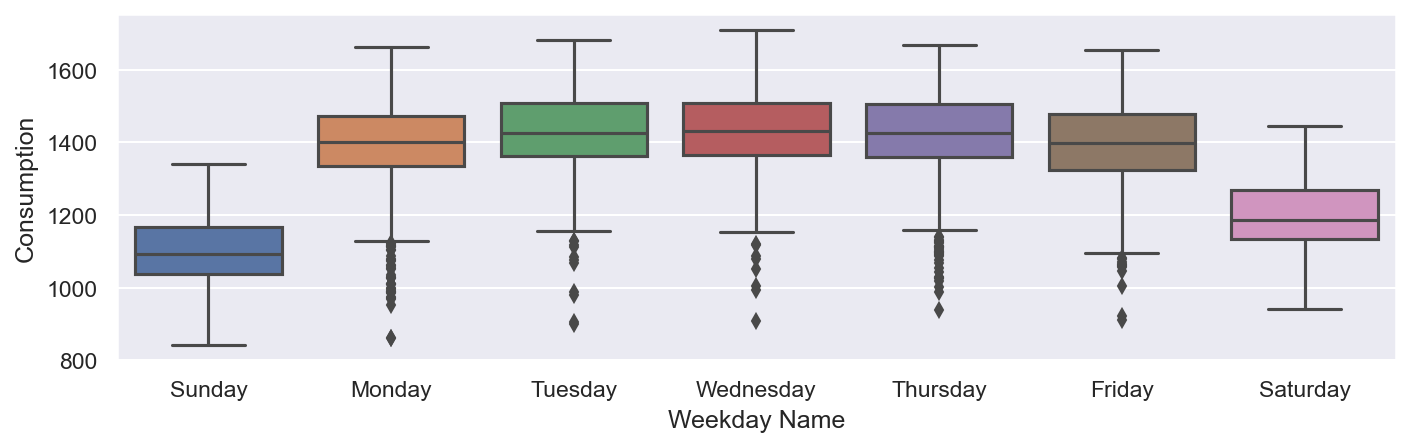
La captura de pantalla anterior muestra que el consumo de electricidad es mayor entre semana que los fines de semana. Curiosamente, hay más valores atípicos entre semana.
Resampling time series data
A menudo es necesario volver a muestrear el conjunto de datos en frecuencias más bajas o más altas. Este remuestreo se realiza en base a operaciones de agregación o agrupación. Por ejemplo, podemos volver a muestrear los datos según la serie temporal media semanal de la siguiente manera:
columns = ['Consumption', 'Wind', 'Solar', 'Wind+Solar']
# resample('W').mean() muestrea el conjunto calculando la media por semana
power_weekly_mean = df[columns].resample('W').mean()
power_weekly_mean
| Consumption | Wind | Solar | Wind+Solar | |
|---|---|---|---|---|
| Date | ||||
| 2006-01-01 | 1069.184000 | NaN | NaN | NaN |
| 2006-01-08 | 1381.300143 | NaN | NaN | NaN |
| 2006-01-15 | 1486.730286 | NaN | NaN | NaN |
| 2006-01-22 | 1490.031143 | NaN | NaN | NaN |
| 2006-01-29 | 1514.176857 | NaN | NaN | NaN |
| ... | ... | ... | ... | ... |
| 2017-12-03 | 1536.236314 | 284.334286 | 18.320857 | 302.655143 |
| 2017-12-10 | 1554.824946 | 636.514714 | 16.440286 | 652.955000 |
| 2017-12-17 | 1543.856889 | 442.531857 | 18.143714 | 460.675571 |
| 2017-12-24 | 1440.342401 | 339.018429 | 9.895143 | 348.913571 |
| 2017-12-31 | 1203.265211 | 604.699143 | 19.240143 | 623.939286 |
627 rows × 4 columns
Como se muestra en la captura de pantalla anterior, la primera fila, denominada 2006-01-01, incluye el promedio de todos los datos. Podemos trazar las series de tiempo diarias y semanales para comparar el conjunto de datos durante el período de seis meses.
Veamos los últimos seis meses de 2016. Empecemos inicializando la variable:
start, end = '2016-01', '2016-06'
# crear el grafico
fig, ax = plt.subplots()
ax.plot(df.loc[start:end, 'Solar'],
marker='.', linestyle='-', linewidth=0.5, label='Daily')
ax.plot(power_weekly_mean.loc[start:end, 'Solar'],
marker='o', markersize=8, linestyle='-', label='Weekly Mean Resample')
ax.set_ylabel('Solar Production in (GWh)')
ax.legend();
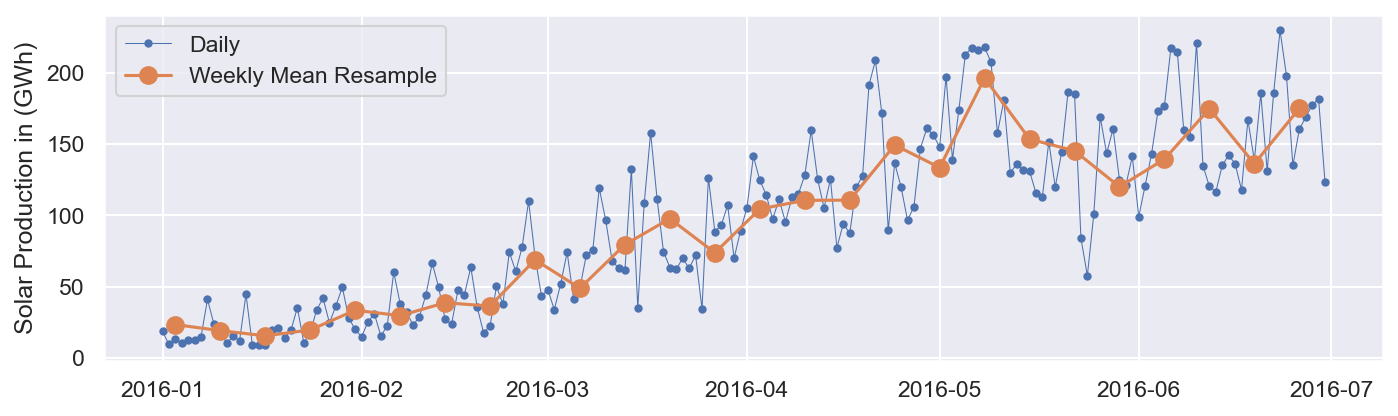
La captura de pantalla anterior muestra que la serie temporal media semanal aumenta con el tiempo y es mucho más suave que la serie temporal diaria.