Centrado y escalado de datos
Como científico de datos, a menudo necesitará transformar sus datos antes de visualizarlos, analizarlos o modelarlos. En este artículo, aprenderá cómo centrar y escalar sus datos utilizando técnicas comunes. Aprenderás:
- Cómo centrar datos e interpretar datos centrados
- Por qué es importante escalar sus datos
- Cómo escalar datos utilizando dos métodos comunes:
- Normalización mín-máx
- Estandarización
- Cuándo elegir normalización versus estandarización
Centrado de datos.
El centrado de datos implica restar la media de un conjunto de datos de cada punto de datos para que la nueva media sea 0. Matemáticamente, esto se ve así:
\[X_{\text{centered}_i} = X_i - \mu\]donde \(X_i\) es un punto de datos y la letra griega \(μ\) es la media de todos los valores \(X\).
Por ejemplo, echemos un vistazo a un conjunto de datos de edades de cinco personas:
ages = [24, 40, 28, 22, 56]
La edad media en este conjunto de datos es 34 años.
Para centrar nuestros datos, restamos la media de cada punto de datos en ages:
centered_ages = [-10, 6, -6, -12, 22]
Estos datos centrados son útiles porque nos dicen qué tan por encima o por debajo de la media está cada punto de datos, lo que nos brinda información adicional que no podemos obtener simplemente mirando el conjunto de datos inicial. Por ejemplo, la edad del primer individuo está diez años por debajo de la media.
Tenga en cuenta que, debido a que la suma de los valores centrados es 0 ( -10 + 6 - 6 - 12 + 22 = 0), la media de los datos centrados es 0.
Escalado de datos
Una tarea común para los analistas de datos y los científicos es encontrar tendencias en los datos comparando las características de los puntos de datos. Sin embargo, esta tarea se vuelve difícil cuando las características están en escalas drásticamente diferentes.
Por ejemplo, consideremos un conjunto de datos que contiene dos características, edad e ingresos.
En general, la edad de una persona suele oscilar entre 0 y aproximadamente 100 años. Los ingresos de una persona, por otro lado, suelen oscilar entre 0 y grandes cantidades medidas en miles de dólares. Es evidente que la edad y los ingresos son dos características que tienen rangos muy diferentes.
Esto presenta problemas cuando se intenta utilizar muchos algoritmos de aprendizaje automático, que tratan todas las dimensiones por igual, independientemente de su escala. La diferencia de un año de edad se interpreta como exactamente igual a la diferencia de un dólar de ingreso. ¡Eso no tiene sentido!
En otras palabras, la característica del ingreso pesa más que la importancia de la edad porque el ingreso es de una escala relativamente enorme. Echa un vistazo a la siguiente imagen:
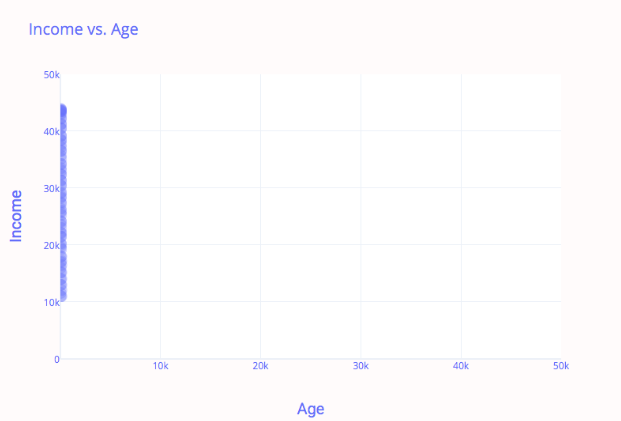
En este gráfico, es imposible notar alguna relación entre los ingresos y la edad: todos los datos están desplazados hacia la izquierda. Esto se debe a que la característica de mayor escala (ingresos) domina a la característica más pequeña (edad).
Nos gustaría que cada punto de datos tuviera la misma escala para que cada característica contribuya por igual a la relación. El escalado de datos nos permite lograr esto.
Dos de las técnicas de escalado de datos más utilizadas son:
- Normalización mín-máx
- Estandarización
Normalización mín.-máx.
La normalización min-max es una de las formas más simples y comunes de escalar datos.
Para cada característica de un conjunto de datos, el valor mínimo de esa característica se transforma en 0, el valor máximo se transforma en 1 y todos los demás valores se transforman en un decimal entre 0 y 1.
Por ejemplo, si el valor mínimo de una característica es 10 y el valor máximo es 30, entonces 20 se transformaría en 0,5 ya que está a medio camino entre 10 y 30.
La fórmula para la normalización min-max es la siguiente:
\[X_{\text{norma}} = \frac{X - X_{\text{min}}}{X_{\text{máximo}} - X_{\text{min}}}\]Usando la normalización min-max, nuestro gráfico anterior de ingresos versus edad se ve así:
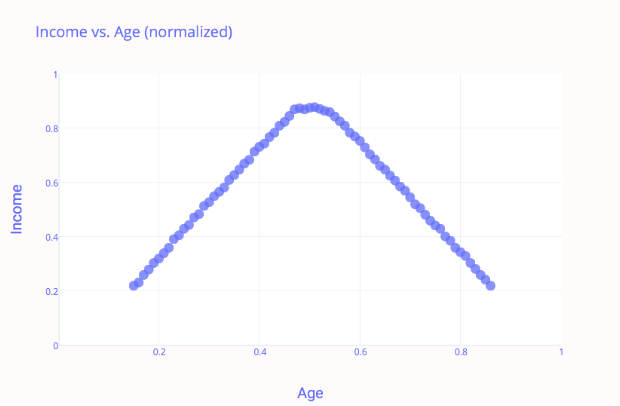
Observe que los datos ahora están escalados correctamente: tanto la edad como los ingresos están en el rango de [0,1].
Para realizar la normalización Min-Max en Python, puedes usar varias bibliotecas. Aquí te muestro algunos métodos usando NumPy, pandas y scikit-learn.
Usando pandas
def min_max_normalize(lst):
minimum = min(lst)
maximum = max(lst)
normalized = [(x - minimum) / (maximum - minimum) for x in lst]
return normalized
# Ejemplo de uso
data = [1, 2, 3, 4, 5]
normalized_data = min_max_normalize(data)
print(normalized_data)
Usando scikit-learn
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
# Ejemplo de uso
data = [[1], [2], [3], [4], [5]]
normalized_data = scaler.fit_transform(data)
print(normalized_data)
Cada método tiene sus propias ventajas dependiendo del contexto y del formato de los datos con los que estés trabajando. La biblioteca scikit-learn es especialmente útil cuando trabajas con datos en aprendizaje automático, ya que ofrece una integración fácil con otros métodos y flujos de trabajo de preprocesamiento.
Una desventaja de la normalización mínimo-máximo es que no maneja muy bien los valores atípicos. Por ejemplo, si tiene 99 valores entre 0 y 20, y un valor es 100, entonces todos los 99 valores se transformarán en un valor entre 0 y 0,2 mientras que el valor atípico se transforma en 1. Esto da como resultado datos sesgados:
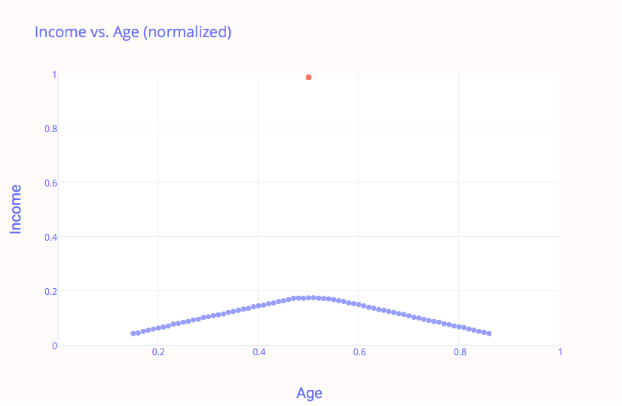
En este ejemplo, la normalización de los datos solucionó el problema de inclinación en el eje x, pero ahora el eje y está causando problemas.
Como veremos en breve, la estandarización es un método de escalamiento de datos más sólido para lidiar con valores atípicos.
Estandarización
La estandarización (también conocida como normalización de puntuación Z ) es otra técnica común de escalado de datos.
La estandarización implica restar la media de cada observación y luego dividirla por la desviación estándar:
\[z = \frac{\text{value} - \text{mean}}{\text{stdev}}\]Una vez completada la estandarización, todas las características tendrán una media de cero, una desviación estándar de uno y, por lo tanto, la misma escala.
A diferencia de la normalización, la estandarización no tiene un rango límite. Esto significa que incluso si tiene valores atípicos en sus datos, sus datos estandarizados no se verán afectados. Por lo tanto, si su conjunto de datos tiene valores atípicos, la estandarización es la técnica de escalamiento preferida.
La fórmula anterior para implementar la estandarización en Python:
def standardize(lst, mean, std_dev):
standardized = [(x - mean) / (std_dev) for x in lst]
# code goes here
return standardized
# Uncomment these function calls to test your standardize function:
print(standardize([1, 2, 3, 4, 5], 3.0, 1.41))
# should print [-1.418, -0.709, 0.0, 0.709, 1.418]
print(standardize([10, 15, 20], 15.0, 4.08))
# should print [-1.225, 0.0, 1.225]
¿Cuándo normalizar o estandarizar?
La normalización y la estandarización mínima-máxima tienen el objetivo similar de transformar características en los datos para que tengan la misma escala, de modo que cada característica sea igualmente importante. Entonces, ¿cuándo debería utilizar la normalización mínima-máxima frente a la estandarización?
No siempre hay una respuesta clara. Tanto la normalización como la estandarización tienen sus ventajas y desventajas. Por ejemplo, si necesita que sus datos estén en una escala de 0 a 1, entonces tiene sentido utilizar la normalización mínima-máxima. Si tiene valores atípicos en sus datos, entonces es mejor utilizar la estandarización ( normalización de puntuación Z ), ya que no tiene un rango límite como lo tiene la normalización mínima-máxima.
Tenga en cuenta que no todos los conjuntos de datos requieren normalización o estandarización. Si las características de sus datos no tienen rangos muy diferentes, es posible que no sea necesario escalar sus datos.
Implementación de
Como vio, es posible implementar la normalización y estandarización mínima-máxima escribiendo sus propias funciones de Python. Sin embargo, en la práctica, la mayoría de los analistas y científicos de datos utilizan bibliotecas populares como scikit-learn, lo que hace que sea muy fácil escalar sus datos.
Por ejemplo, para normalizar sus datos, puede importarlos MinMaxScalerdesde el sklearn.preprocessingpaquete y luego realizar una llamada de función simple:
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
# read in data
data = pd.read_csv('data.csv')
# normalize data
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)
Del mismo modo, estandarizar sus datos es fácil de hacer con solo unas pocas líneas de código:
from sklearn.preprocessing import StandardScaler
import pandas as pd
# read in data
data = pd.read_csv('data.csv')
# standardize data
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)