Discretizar datos numéricos y contraer categorías
En este artículo, aprenderá técnicas de transformación simples para datos numéricos y categóricos que ayudarán a que sus datos sean más fáciles de analizar, que incluyen:
- Qué significa agrupar datos numéricos y por qué es importante
- Cómo agrupar datos numéricos en Python
- Por qué combinar datos categóricos puede ser útil para el análisis/visualización
- Cómo combinar datos categóricos en Python
Agrupación de datos
Como analista de datos o científico, a veces tendrá que trabajar con datos numéricos que le gustaría organizar en diferentes categorías. Por ejemplo, imagina que estás mirando las edades de un conjunto de individuos. Es posible que le importe más la categoría de edad a la que pertenece cada persona (20-29, 30-39, 40-49, etc.) que la edad exacta. El proceso de transformar variables numéricas en contrapartes categóricas se llama “binning”.
La agrupación es una forma de agrupar una cantidad de valores continuos en una cantidad menor de “contenedores”. Esto lo vemos en el mundo real con bastante frecuencia. Por ejemplo, la calificación con letras de un estudiante está determinada por el porcentaje en el que se encuentra. Además, la tasa impositiva de un individuo está determinada por el “grupo” de ingresos al que pertenece.
¿Por qué agrupar datos?
La agrupación de datos puede resultar útil en muchas situaciones, ya sea para crear visualizaciones más atractivas o para mejorar un modelo de aprendizaje automático.
En áreas como el aprendizaje automático, la agrupación de datos puede resultar útil para mejorar la precisión de los modelos predictivos al reducir el ruido de los datos. Por ejemplo, si es un ingeniero de aprendizaje automático que trabaja en una empresa de inversión, puede utilizar la agrupación como técnica para mejorar sus modelos de predicción de acciones suavizando los datos para reducir el impacto de pequeños cambios de precios a corto plazo.
Ahora que comprende mejor por qué agrupamos datos, ¡exploremos cómo agrupar datos numéricos en Python!
Agrupación de datos numéricos en Python
En este ejemplo, veremos las edades de los estudiantes de una clase de baile (almacenadas en un archivo llamado dance_class_data.csv).
import pandas as pd
# Load in data
dance_class = pd.read_csv('dance_class_data.csv')
# Print the first 10 rows
print(dance_class.head(10))
La salida se parece a:
Name Gender Age Experience
0 Chris Shelton M 23 beginner
1 Douglas Watson M 28 intermediate
2 Martha Gomez F 45 beginner
3 Amos Moore M 63 beginner
4 Valentina Sen F 35 beginner
5 Billy Woods M 53 advanced
6 Oscar Barker M 43 intermediate
7 Marie Sandoval F 23 beginner
8 Nancy Mcbride F 35 beginner
9 Lindsay Bowen F 27 beginner
El marco de datos dance_class tiene cuatro columnas: Name, Gender, Age y Experience. Podemos averiguar los tipos de datos de estas columnas usando la propiedad dtypes:
print(dance_class.dtypes)
La salida se parece a:
Name object
Gender object
Age int64
Experience object
Observe que la columna Age es de tipo int. Esta es la columna que exploraremos.
Tenemos curiosidad por ver en qué rango de edad se encuentra cada estudiante de la clase. Para hacer esto, podemos agrupar los valores en grupos de edad específicos. Antes de hacer eso, almacenemos la edad de los estudiantes y averigüemos las edades mínima y máxima:
# Store the ages
student_ages = dance_class['Age']
# min() method returns the lowest value
print(student_ages.min()) # 23
# max() method returns the highest value
print(student_ages.max()) # 65
El alumno más joven de la clase tiene 23 años y el mayor 65 años. Por lo tanto, podemos definir los límites de nuestros contenedores por década (20-29, 30-39, 40-49, 50-59, 60-69).
Primero creemos una variable bins para almacenar estos valores:
# Store the boundaries
bins = [20, 30, 40, 50, 60, 70]
A continuación, podemos crear los contenedores usando pd.cut(df['column_name'], bins).
Un número entero que especifica el número de contenedores espaciados uniformemente, o Una lista de límites de contenedores. Agrupemos el valor de la columna Age en contenedores del mismo tamaño en una nueva columna llamada binned_age. Luego, imprimamos las primeras filas de los datos:
# Create new binned_age column that bins the values of the ‘Age’ column
dance_class['binned_age'] = pd.cut(dance_class['Age'], bins)
# Print the first few rows of the data
print(dance_class[['binned_age', 'Age']].head())
La salida se parece a:
binned_age Age
0 (20, 30] 23
1 (20, 30] 28
2 (40, 50] 45
3 (60, 70] 63
4 (30, 40] 35
Observe cómo cada edad ahora pertenece a un grupo de edad específico. También podemos trazar nuestros datos en un gráfico de barras para obtener una mejor visualización:
# Plot the bar graph of binned ages
dance_class['binned_age'].value_counts().plot(kind='bar')
# Label the bar graph
plt.title('Dance Class Age Distribution')
plt.xlabel('Ages')
plt.ylabel('Count')
# Show the bar graph
plt.show()
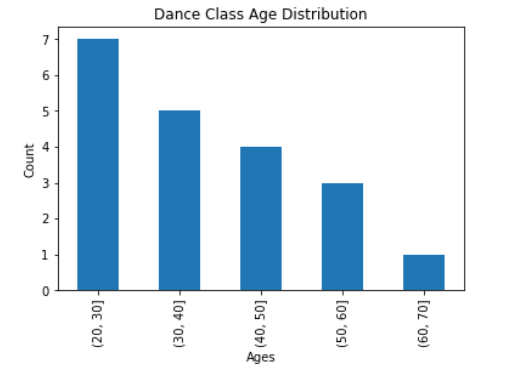
Observe cómo los datos se clasifican en diferentes grupos de edad, lo que nos permite ver el panorama general de nuestros datos sin centrarnos demasiado en las edades precisas de cada individuo. Con base en este gráfico, podemos ver que la clase se inclina hacia edades más jóvenes.
Si queremos, también podemos especificar etiquetas para nuestros contenedores usando el argumento labels:
# Store the boundaries
bins = [20, 30, 40, 50, 60, 70]
# Store the labels for our bins
age_labels = ['Young Adult', 'Adult', 'Middle Aged', 'Middle-Older Age', 'Senior']
# Bin the values of the 'Age' column and specify the labels
dance_class['binned_age'] = pd.cut(dance_class['Age'], bins, labels = age_labels)
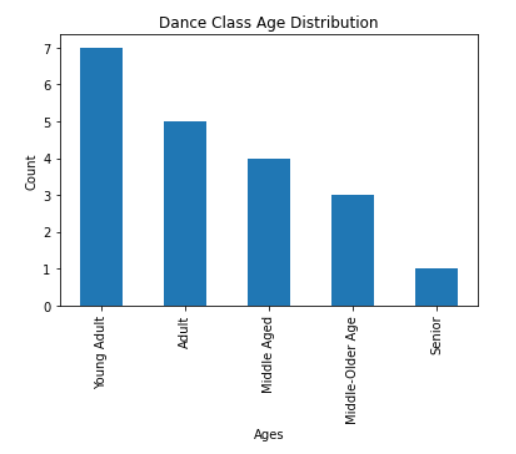
Ahora, cuando imprimimos las primeras filas de nuestros datos o trazamos un gráfico de barras de los datos, cada rango numérico que especificamos anteriormente se reemplaza con la etiqueta asignada:
binned_age Age
0 Young Adult 23
1 Young Adult 28
2 Middle Aged 45
3 Senior 63
4 Adult 35
Combinando datos categóricos
Como analista de datos o científico, a veces trabajará con datos categóricos. Solo como repaso, los datos categóricos son variables que contienen valores de etiqueta en lugar de valores numéricos. Por ejemplo,
Cuando se trata de datos categóricos, es posible que en ocasiones desee combinar o eliminar categorías para facilitar el análisis. Por ejemplo, imagina que estás mirando un conjunto de datos de los deportes más populares en una región:
Sport Count
Basketball 500
Football 400
Baseball 8
Tennis 7
Cricket 4
Sailing 3
Tenga en cuenta que aquí hay varias categorías de deportes, pero una distribución bastante desigual de sus ocurrencias. El baloncesto y el fútbol constituyen una abrumadora mayoría de los datos, mientras que las otras categorías sólo tienen unas pocas apariciones. Por lo tanto, puede tener sentido combinar todos los demás deportes en una categoría llamada “Otros”.
Sport Count
Basketball 500
Football 400
Others 22
Combinando categorías en Python
Exploremos cómo combinar categorías de datos categóricos en Python. Trabajaremos con un conjunto de datos llamado election_poll.csv para ver los candidatos más populares para las elecciones del concejo municipal. Este conjunto de datos tiene usaremos una columna llamada Votes.
Primero, importemos nuestros datos y veamos los recuentos de cada uno de los candidatos (categorías) en nuestros datos:
import pandas as pd
# read in data
election_data = pd.read_csv('election_data.csv')
# get the counts for each candidate
votes = election_data['Vote'].value_counts()
print(votes)
La salida se parece a:
Liliana 1067
John 998
William 494
Emilie 196
Pattie 6
Neil 3
Bob 2
Demi 1
David 1
Hester 1
¿Qué notas sobre los datos? ¿Hay candidatos específicos en los que deberíamos centrarnos más y otros en los que deberíamos centrarnos menos?
Puede notar que Liliana, Johny William constituyen la mayor parte de los datos, mientras que los otros candidatos representan un porcentaje menor del recuento general de votos. Si intentamos comprender la probabilidad de que cada uno de estos candidatos sea elegido en una próxima votación, tiene sentido agrupar a los demás candidatos en una categoría llamada “Otros”. Si decidiéramos no hacer esto, entonces nuestro análisis podría ser más difícil de analizar. Por ejemplo, si tuviéramos que representar estos datos en un gráfico circular, se vería así:
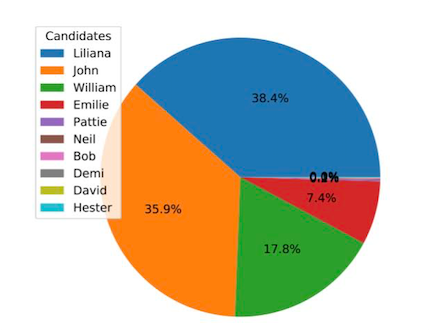
Ese no es un gráfico circular agradable de ver. Liliana, John y William representan el 92 % de los datos, mientras que las otras siete categorías representan solo el 8 % de los datos. Una vez que combinamos esas siete categorías en una categoría “Otro”, el gráfico circular se ve así:
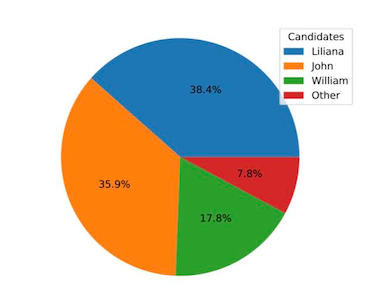
¿Cómo podemos hacer esto en Python? Podemos crear una máscara para valores que aparecen menos de un número específico de veces en votes. En nuestro caso, comprobaremos los valores que aparecen menos de 200 veces. Hacemos esto usando la función isin():
mask = election_data.isin(votes[votes < 200].index)
A continuación, podemos etiquetar estas otras categorías como “Otras” e imprimir el recuento de votos actualizado:
election_data[mask] = 'Other'
print(election_data['Vote'].value_counts())
Salida
Liliana 1067
John 998
William 494
Other 210
Name: Vote, dtype: int64
Observe cuán limpios están los datos ahora que hemos combinado las siete categorías de baja frecuencia en una categoría “Otros”.
Recuerde que cuanto más limpios estén sus datos, más sencillo será analizarlos y visualizarlos, por lo que tomarse el tiempo para comprender sus datos y aplicar transformaciones simples como esta cuando sea apropiado será de gran ayuda.