Transformación de datos
Uno de los pasos fundamentales del Análisis Exploratorio de Datos (EDA) es el Data Wrangling. La trasnformacion de datos es un conjunto de técnicas utilizadas para convertir datos de un formato o estructura a otro formato o estructura.
En el proceso de preparación de datos, ciertas tareas suelen realizarse en un orden específico para maximizar la eficiencia y efectividad del flujo de trabajo. Aquí está la lista reordenada de acuerdo con un flujo de trabajo típico de limpieza y preparación de datos:
-
Key restructuring (reestructuración de claves) Consiste en transformar claves con significados específicos en claves genéricas para facilitar su uso y análisis. Ejemplo: Cambiar un identificador de producto específico del proveedor a un identificador universal.
-
Data Validation (validación de datos) Es el proceso de aplicar reglas o algoritmos para verificar la precisión y la integridad de los datos en relación con ciertos criterios o estándares. Ejemplo: Verificar si los números de teléfono en una base de datos siguen un formato específico.
-
Data Cleaning (limpieza de datos) Implica la eliminación o corrección de datos inexactos, incompletos, obsoletos o irrelevantes para mejorar la calidad general de los datos. Ejemplo: Eliminar espacios en blanco adicionales alrededor de los valores en una columna de datos.
-
Data deduplication (deduplicación de datos) Implica la identificación y eliminación de registros duplicados dentro de un conjunto de datos para mejorar la calidad y la precisión de los datos. Ejemplo: Eliminar entradas duplicadas en una base de datos de clientes.
-
Data derivation (derivación de datos) Implica la creación de nuevas variables o atributos a partir de datos existentes utilizando reglas o algoritmos definidos. Ejemplo: Calcular la edad de los clientes a partir de su fecha de nacimiento.
-
Format revisioning (revisión de formato) Consiste en convertir datos de un formato a otro para facilitar su análisis o integración con otros sistemas. Ejemplo: Convertir una fecha de formato de texto a formato de fecha y hora estándar.
-
Data aggregation (agregación de datos) Consiste en buscar, extraer, resumir y preservar información importante en diferentes sistemas de informes para facilitar el análisis. Ejemplo: Sumar las ventas mensuales para obtener ventas anuales totales.
-
Data filtering (filtrado de datos) Implica identificar y seleccionar solo los datos relevantes para un análisis específico, descartando datos irrelevantes o no deseados. Ejemplo: Filtrar registros de ventas para mostrar solo transacciones realizadas en un período de tiempo específico.
-
Data joining (unión de datos) Consiste en combinar dos o más conjuntos de datos relacionados mediante una clave común para realizar análisis conjunto. Ejemplo: Unir datos de clientes con datos de pedidos utilizando un identificador único de cliente.
-
Data integration (integración de datos) Involucra combinar datos de múltiples fuentes y formatos en un único esquema o estructura para análisis coherente. Ejemplo: Integrar datos de ventas de diferentes sucursales en una sola base de datos.
Este flujo de trabajo es iterativo y puede requerir ajustes en función de las necesidades específicas del proyecto y la naturaleza de los datos. Además, algunos pasos pueden superponerse o requerir ir y volver, especialmente en proyectos complejos o cuando surgen nuevos datos o requisitos de análisis.
La razón principal para transformar los datos es obtener una mejor representación de modo que los datos transformados sean compatibles con otros datos. Además de esto, la interoperabilidad en un sistema se puede lograr siguiendo una estructura y un formato de datos comunes.
Top
Key Restructuring
En el ámbito de la ciencia de datos, “Key Restructuring” se refiere a la reorganización o transformación de las claves en un conjunto de datos. Las “claves” en este contexto suelen ser identificadores únicos o conjuntos de campos que sirven para relacionar registros entre sí.
Renombrar Claves
Para renombrar claves (es decir, los nombres de las columnas que actúan como claves), puedes utilizar el método rename():
df.rename(columns={'old_name': 'new_name'}, inplace=True)
Reasignar Valores de Clave
Cambiar los valores dentro de las claves mismas, lo que se puede hacer con operaciones de mapeo o aplicando funciones:
df['key_column'] = df['key_column'].map(lambda x: 'new_value' if condition else x)
Crear Claves Compuestas
Una clave compuesta es una clave única que se compone de la combinación de dos o más columnas:
df['composite_key'] = df['key_part1'].astype(str) + '-' + df['key_part2'].astype(str)
Eliminación de Claves Innecesarias
Puedes eliminar claves que ya no son necesarias o que podrían causar confusión en el análisis de datos:
df.drop(columns=['unnecessary_key'], inplace=True)
Asegurar la Unicidad
Es importante garantizar que las claves sean únicas antes de realizar operaciones como combinaciones. Puedes verificar la unicidad de las claves y eliminar duplicados si es necesario:
if df['key_column'].is_unique:
print("Las claves son únicas.")
else:
df.drop_duplicates(subset=['key_column'], inplace=True)
Reindexación Basada en Claves
Finalmente, puedes querer reindexar tu DataFrame para que las claves sean el nuevo índice:
df.set_index('key_column', inplace=True)
Top
Data Validation
El proceso de verificar si los datos cumplen con un conjunto de reglas o normas antes de ser procesados o analizados. Es una etapa crítica en el ciclo de vida de la ciencia de datos, ya que trabajar con datos erróneos o mal formateados puede llevar a conclusiones incorrectas y afectar la calidad de los resultados del análisis.
En Pandas, hay varias técnicas y herramientas que puedes usar para realizar la validación de datos.
Usar Métodos de String para Validación de Texto: que te permiten validar y limpiar datos de texto. Estos métodos se aplican a las columnas de tipo str.Verificar valores nulos: Comprobar y manejar valores nulosVerificación de Tipos de Datos:Una de las validaciones más básicas es asegurarse de que las columnas tienen el tipo de dato correctoAplicar Condiciones de Validación: aplicar condiciones de validación y usar máscaras booleanas para filtrar datos que no cumplan con ciertos criterios.Rangos de valores: Asegurarte de que los datos estén dentro de un rango esperado es otra forma común de validación.Valores consistentes: Para datos categóricos, a menudo necesitas validar que los valores pertenecen a un conjunto de categorías definidas.Validación Cruzada Entre Columnas: En ocasiones, la validación de una columna depende de los valores en otra columna, lo cual requiere validación cruzada.Manejo de Errores: Cuando se utilizaassert, el código arrojará una excepciónAssertionErrorsi la condición no es verdadera. Debes manejar estos errores de manera adecuada.Validación en la Carga de Datos: Pandas también permite especificar tipos de datos al momento de cargar datos (por ejemplo, conpd.read_csv(dtype=...)), lo cual puede ser una forma temprana de validación.Retroalimentación de la Validación: Es importante no solo identificar dónde los datos no cumplen con las expectativas, sino también proporcionar retroalimentación adecuada para corregir las fuentes de los datos si es posible.
La validación de datos es un proceso continuo y debe adaptarse específicamente a las necesidades y reglas de negocio relevantes para tu análisis o modelo. Cada conjunto de datos puede requerir un conjunto diferente de validaciones, dependiendo de su origen, complejidad y cómo se va a utilizar en el análisis.
Verificación de Tipos de Datos
Una de las validaciones más básicas es asegurarse de que las columnas tienen el tipo de dato correcto (por ejemplo, numérico, cadena de texto, fecha/hora).
# Verificar el tipo de dato de cada columna
df.dtypes
# Convertir una columna a un tipo de dato específico
df['column'] = df['column'].astype(type)
Aplicar Condiciones de Validación
Puedes aplicar condiciones de validación y usar máscaras booleanas para filtrar datos que no cumplan con ciertos criterios.
# Verificar que todos los valores en una columna sean positivos
assert (df['column'] > 0).all()
Usar Métodos de String para Validación de Texto
Pandas tiene métodos de string que te permiten validar y limpiar datos de texto. Estos métodos se aplican a las columnas de tipo str.
# Verificar si el texto de una columna cumple con un patrón (regex)
df['text_column'].str.match(r'^\w+$')
# Extraer partes de una cadena que cumple con un patrón
df['text_column'].str.extract(r'(pattern)')
Valores Nulos o Faltantes
Comprobar y manejar valores nulos es una parte importante de la validación de datos.
# Verificar la presencia de valores nulos
df.isnull().sum()
# Eliminar filas con valores nulos
df.dropna(subset=['column'], inplace=True)
Valores Únicos y Duplicados
Garantizar la unicidad en ciertas columnas puede ser crucial, especialmente para las claves primarias.
# Verificar si los valores en una columna son únicos
df['column'].is_unique
# Eliminar duplicados basados en una o más columnas
df.drop_duplicates(subset=['column1', 'column2'], inplace=True)
Rangos de Valores
Asegurarte de que los datos estén dentro de un rango esperado es otra forma común de validación.
# Verificar que todos los valores de una columna estén dentro de un rango
df[(df['column'] >= min_value) & (df['column'] <= max_value)]
Valores Consistentes
Para datos categóricos, a menudo necesitas validar que los valores pertenecen a un conjunto de categorías definidas.
# Verificar que los valores de una columna estén en un conjunto de categorías
allowed_values = {'cat1', 'cat2', 'cat3'}
df['category_column'].isin(allowed_values)
Utilizando pd.Series y Funciones Personalizadas
Puedes usar apply() con una función personalizada para validar datos de manera más específica.
# Aplicar una función de validación personalizada a cada valor de una columna
df['column'].apply(lambda x: my_validation_function(x))
Validación Cruzada Entre Columnas
En ocasiones, la validación de una columna depende de los valores en otra columna, lo cual requiere validación cruzada.
# Validar una columna basada en los valores de otra
df.apply(lambda row: row['column1'] < row['column2'], axis=1)
Esta operación valida que el valor en column1 sea menor que el valor en column2 para cada fila.
Consideraciones Importantes
Manejo de Errores:Cuando se utilizaassert, el código arrojará una excepciónAssertionErrorsi la condición no es verdadera. Debes manejar estos errores de manera adecuada.Validación en la Carga de Datos:Pandas también permite especificar tipos de datos al momento de cargar datos (por ejemplo, conpd.read_csv(dtype=...)), lo cual puede ser una forma temprana de validación.Retroalimentación de la Validación:Es importante no solo identificar dónde los datos no cumplen con las expectativas, sino también proporcionar retroalimentación adecuada para corregir las fuentes de los datos si es posible.
La validación de datos es un proceso continuo y debe adaptarse específicamente a las necesidades y reglas de negocio relevantes para tu análisis o modelo. Cada conjunto de datos puede requerir un conjunto diferente de validaciones, dependiendo de su origen, complejidad y cómo se va a utilizar en el análisis.
Top
Data Cleaning
El objetivo es detectar y corregir (o eliminar) registros corruptos o inexactos de un conjunto de datos, tratar los valores faltantes, estandarizar o normalizar datos y realizar cualquier otra acción que mejore la calidad de los datos. Al gunas tareas son:
El proceso de limpieza de datos (“data cleaning” en inglés) con Pandas en Python es fundamental para asegurar la calidad de los datos antes de proceder al análisis. El objetivo es detectar y corregir (o eliminar) registros corruptos o inexactos de un conjunto de datos, tratar los valores faltantes, estandarizar o normalizar datos y realizar cualquier otra acción que mejore la calidad de los datos.
Detectar valores faltantes:
df.isnull() # Devuelve un DataFrame con la marca True en los lugares donde hay valores faltantes.
df.isna() # Alias de isnull().
df.notnull() # Devuelve lo contrario de isnull().
Eliminar datos faltantes:
df.dropna() # Elimina filas con valores NA.
df.dropna(axis=1) # Elimina columnas con valores NA.
Rellenar datos faltantes:
df.fillna(value) # Rellena los valores NA con un valor específico.
df.fillna(method='ffill') # Propaga el último valor válido hacia adelante para rellenar los NA.
df.fillna(method='bfill') # Usa el siguiente valor válido para llenar hacia atrás los NA.
Conversión de tipos de datos:
df.astype({'col1': 'int32', 'col2': 'float64'}) # Cambia el tipo de datos de una o más columnas.
Normalización de cadenas de texto:
df['col'].str.lower() # Convierte texto a minúsculas.
df['col'].str.upper() # Convierte texto a mayúsculas.
df['col'].str.strip() # Elimina espacios al inicio y al final.
Aplicación de una función personalizada:
df['col'].apply(lambda x: custom_function(x)) # Aplica una función a cada elemento de la columna.
Manejo de outliers:
Los métodos para manejar outliers varían ampliamente, pero podrías querer filtrarlos o imputarlos en función de medidas estadísticas como la media y la desviación estándar, o basándote en percentiles.
Descomposición y extracción de características:
df['col'].str.split(' ', expand=True) # Separa una columna en varias basándose en un delimitador.
df['col'].str.extract('(\d+)') # Extrae grupos de una columna basándose en una expresión regular.
Mapeo de datos a un rango o a categorías:
df['col'].map({'old_value': 'new_value'}) # Cambia valores específicos en una columna.
df['col'].replace(['old_value1', 'old_value2'], 'new_value') # Reemplaza varios valores con uno nuevo.
Transformación de datos con groupby:
df.groupby('col').transform('mean') # Aplica una función de agregación y distribuye los resultados.
Verificación de la consistencia de los datos, consistencia en categorías:
df['col'].unique() # Verifica los valores únicos para identificar inconsistencias.
Validación de rangos:
df[(df['col'] >= min_value) & (df['col'] <= max_value)] # Filtra datos fuera de un rango específico.
Trabajo con Fechas y Horas, conversión a fecha y hora:
pd.to_datetime(df['date_col'], errors='coerce') # Convierte una columna a datetime, gestionando errores.
Descomposición en componentes más detallados:
df['date_col'].dt.year # Extrae el año.
df['date_col'].dt.month # Extrae el mes.
df['date_col'].dt.day # Extrae el día.
Guardar el DataFrame Limpio
Una vez limpios los datos, es buena práctica guardar el DataFrame resultante en un archivo para futuros análisis.
df.to_csv('clean_data.csv', index=False) # Guarda el DataFrame en un archivo CSV sin el índice.
Top
Data Deduplication
La deduplicación de datos, en el contexto de la ciencia de datos, es el proceso de identificar y eliminar registros duplicados dentro de un conjunto de datos. Los datos duplicados pueden surgir por diversas razones, como la integración de datos de múltiples fuentes, errores en la entrada de datos, o como resultado de procesos de recopilación de datos.
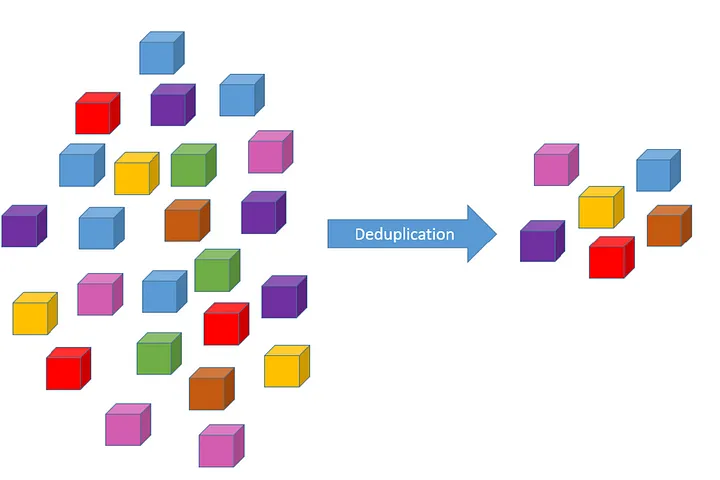
Estrategias de Deduplicación en la Práctica
- Análisis Exploratorio de Datos (EDA): Antes de eliminar duplicados, es importante realizar un EDA para entender por qué aparecen duplicados y asegurarse de que su eliminación no sesgará los análisis posteriores.
- Deduplicación basada en columnas específicas: En algunos casos, puede ser deseable eliminar duplicados basándose solo en algunas columnas que deben ser únicas, utilizando el argumento subset.
- Registros Completos vs. Incompletos: Al deduplicar, considera la posibilidad de mantener el registro más completo (por ejemplo, con menos valores NA) en cada conjunto de duplicados.
df.drop_duplicates()
Este es el método más directo para eliminar filas duplicadas de un DataFrame. Por defecto, drop_duplicates() elimina las filas que tienen todas sus columnas idénticas a otra fila, manteniendo la primera ocurrencia de cada conjunto de duplicados y descartando el resto.
Puedes modificar su comportamiento con argumentos como subset, para especificar un subconjunto de columnas para considerar en la búsqueda de duplicados, y keep, para indicar cuál de los duplicados mantener ('first', 'last', o False para eliminar todos los duplicados).
df = df.drop_duplicates()
df.duplicated()
Mientras que .drop_duplicates() se usa para eliminar duplicados, .duplicated() es útil para marcar los duplicados. Este método retorna una Serie booleana que indica si cada fila es un duplicado (basado en todas las columnas o un subconjunto especificado) de una fila anterior. Esto es especialmente útil para explorar los datos y entender la naturaleza de los duplicados antes de decidir cómo manejarlos.
df = df.duplicates()
Top
Data Derivation
Se refiere al proceso de crear nuevos datos basados en datos ya existentes. Esto implica aplicar un conjunto de reglas o algoritmos para extraer o generar información adicional a partir de los datos originales. En la ciencia de datos, es una técnica comúnmente utilizada para enriquecer el conjunto de datos y facilitar el análisis posterior o la construcción de modelos de aprendizaje automático.
Cálculo de características estadísticas:
A partir de datos numéricos, se pueden derivar medias, medianas, desviaciones estándar, sumas, etc., ya sea a lo largo del tiempo, por categorías, o para el conjunto de datos completo.
df['average'] = df['data'].mean()
Transformaciones matemáticas:
Aplicación de fórmulas matemáticas a los datos para obtener nuevas columnas. Por ejemplo, normalización de datos, cambio de escala, etc.
df['normalized'] = (df['data'] - df['data'].mean()) / df['data'].std()
Descomposición de fechas y horas:
Extracción de año, mes, día, hora, minuto o segundo de campos de fecha y hora para analizar tendencias temporales o ciclos.
df['year'] = df['date'].dt.year
Concatenación o separación de texto:
Unir o dividir cadenas para formar identificadores únicos o separar información compuesta en varios componentes.
df['full_name'] = df['first_name'] + ' ' + df['last_name']
Creación de indicadores:
Transformar variables categóricas en una serie de indicadores binarios, a menudo conocido como “one-hot encoding”.
df = pd.concat([df, pd.get_dummies(df['category'])], axis=1)
Interacciones de características:
Combinar características mediante multiplicación o cualquier otra operación para capturar interacciones entre ellas en modelos predictivos.
df['interaction'] = df['feature1'] * df['feature2']
Binning o discretización:
Convertir variables continuas en categóricas a través de la creación de intervalos.
df['binned'] = pd.cut(df['continuous_variable'], bins=3)
Cálculo de diferencias y cambios:
Para series temporales o datos ordenados, calcular la diferencia o el cambio porcentual entre filas consecutivas.
df['difference'] = df['data'].diff()
df['pct_change'] = df['data'].pct_change()
Aplicación de condiciones lógicas:
Crear nuevas columnas con valores basados en condiciones lógicas aplicadas a los datos.
df['is_adult'] = df['age'].apply(lambda x: True if x >= 18 else False)
Extracción de información de texto:
Utilizar expresiones regulares o métodos de procesamiento de lenguaje natural para extraer información como nombres, fechas, y entidades clave de textos.
df['email_domain'] = df['email'].str.extract(r'@(\w+.\w+)')
La derivación de datos es una práctica que no solo mejora la comprensión de los datos, sino que también puede revelar patrones ocultos, simplificar modelos predictivos y mejorar la precisión de los análisis. En Pandas, la derivación de datos se beneficia del amplio conjunto de operaciones vectorizadas y de las funciones de alto rendimiento, que permiten manipular y transformar grandes conjuntos de datos de forma eficiente.
Top
Format Revisioning
La revisión de formato, o “Format Revisioning”, en el contexto de la ciencia de datos, implica convertir datos de un formato a otro para mejorar su usabilidad, compatibilidad o para prepararlos para análisis específicos. Este proceso es esencial cuando se trabaja con conjuntos de datos que provienen de diversas fuentes y pueden no estar en el formato deseado para análisis o procesamiento posterior. A continuación, se detallan algunas tareas y métodos comunes para la revisión de formato:
Métodos comunes en Pandas
Convertir tipos de datos de columnas:
Es común necesitar cambiar el tipo de datos de las columnas, por ejemplo, convertir una columna de tipo objeto a tipo numérico o a tipo datetime.
df['columna'] = pd.to_numeric(df['columna'], errors='coerce')
df['fecha'] = pd.to_datetime(df['fecha'])
Normalización de Textos
A menudo, los datos textuales necesitan ser normalizados a un formato común para garantizar la consistencia.
df['texto'] = df['texto'].str.lower() # Convertir a minúsculas
df['texto'] = df['texto'].str.strip() # Eliminar espacios en blanco al inicio y al final
Formateo de Datos Numéricos
Cambio de representación numérica:
df['entero'] = df['flotante'].astype(int)
Trabajar con Fechas y Horas
Conversión y extracción de componentes de fechas:** Pandas facilita la conversión de strings a objetos datetime y la extracción de componentes como año, mes, día, etc.
df['datetime'] = pd.to_datetime(df['fecha_str'])
df['año'] = df['datetime'].dt.year
Conversión a categorías
Para datos con un número limitado de valores únicos, convertirlos a tipo categórico puede ser más eficiente en términos de memoria.
df['categoría'] = df['categoría'].astype('category')
Exportación a Diferentes Formatos
Una vez que los datos están en el formato deseado, Pandas ofrece múltiples funciones para exportar los datos a diversos formatos para su uso en otras aplicaciones, análisis o almacenamiento.
df.to_csv('datos.csv', index=False)
df.to_excel('datos.xlsx', sheet_name='Hoja 1', index=False)
df.to_json('datos.json')
df.to_html('datos.html')
df.to_sql('nombre_tabla', con=conexion, if_exists='replace', index=False)
Top
Data aggregation
La agregación de datos es un paso crítico en el análisis de datos, particularmente útil para resumir o extraer información valiosa de un conjunto de datos. En Pandas, esta fase implica combinar datos de múltiples filas en un solo resumen. Aquí hay una visión general de las tareas y métodos comunes utilizados en Pandas para la agregación de datos:
GroupBy: Agrupación de Datos
La función .groupby() es central para la mayoría de las tareas de agregación en Pandas. Permite agrupar datos en categorías basadas en una o más columnas y aplicar una función de agregación a cada grupo.
df.groupby('columna_categorica')['columna_a_agregar'].sum()
Agregaciones Múltiples con .agg()
Puedes realizar múltiples agregaciones en un solo paso con el método .agg(), pasando una lista de funciones de agregación que quieres aplicar a las columnas.
df.groupby('columna_categorica').agg({'columna_a_agregar1': 'sum',
'columna_a_agregar2': ['mean', 'std']})
Pivot Tables: Tablas Pivote
Las tablas pivote son útiles para resumir datos y ver la relación entre dos dimensiones de manera tabular. En Pandas, puedes crear una tabla pivote con .pivot_table().
df.pivot_table(values='columna_a_agregar', index='columna_categorica', columns='otra_columna_categorica', aggfunc='mean')
Crosstab: Tablas de Contingencia
Para agregación de frecuencias o conteo cruzado entre dos (o más) columnas, puedes usar la función pd.crosstab().
pd.crosstab(df['columna_categorica1'], df['columna_categorica2'])
Rolling y Expanding: Agregaciones Móviles
Para series temporales, a menudo es útil calcular estadísticas móviles (como la media móvil) o estadísticas acumulativas. Pandas ofrece .rolling() y .expanding() para estos propósitos.
df['columna_numerica'].rolling(window=5).mean() # Media móvil
df['columna_numerica'].expanding().sum() # Suma acumulativa
Resample: Reagrupación Temporal
El método .resample() es específicamente útil para series temporales, permitiendo cambiar la frecuencia de los datos (por ejemplo, de diaria a mensual) y aplicar una función de agregación.
df.resample('M')['columna_numerica'].sum()
Transform: Aplicación de Transformaciones con Retención de Forma
A veces, necesitas aplicar una función de agregación pero mantener el mismo tamaño del DataFrame original. Esto es posible con .transform().
df.groupby('columna_categorica')['columna_numerica'].transform('mean')
Métodos de Agregación Personalizados
Para necesidades de agregación más específicas, puedes definir tus propias funciones de agregación y aplicarlas usando .apply() en un DataFrame o Serie agrupado.
def rango(x):
return x.max() - x.min()
df.groupby('columna_categorica')['columna_numerica'].apply(rango)
Top
Data Filtering
El filtrado de datos es una etapa crucial en el análisis de datos que implica seleccionar subconjuntos de datos basados en ciertos criterios. En Pandas, esto generalmente se realiza utilizando condiciones booleanas, métodos específicos y funcionalidades de indexación. Estos métodos permiten a los usuarios seleccionar datos que cumplan con condiciones específicas, excluyendo aquellos que no las cumplen. Aquí te explico algunas tareas y métodos comunes utilizados en Pandas para el filtrado de datos:
Filtrado Básico con Condiciones Booleanas
Puedes usar condiciones booleanas directamente en un DataFrame para filtrar filas. Este es el método más directo y se basa en operadores de comparación.
df_filtrado = df[df['columna'] > valor]
Uso de .loc[] para Filtrado Avanzado
El método .loc[] permite filtrar filas y seleccionar columnas por etiqueta. Es útil para aplicar condiciones complejas.
df_filtrado = df.loc[df['columna'] > valor, ['columna1', 'columna2']]
Uso de .query() para Filtrado con Expresiones de Cadenas
El método .query() permite filtrar un DataFrame utilizando una expresión de cadena que puede ser más legible y concisa, especialmente para filtros complejos.
df_filtrado = df.query('columna > valor')
Filtrado Basado en Índices
Si el DataFrame tiene un índice significativo (por ejemplo, fechas), puedes filtrar basándote en este índice directamente.
df_filtrado = df[df.index > '2022-01-01']
Uso de Métodos Específicos para Filtrar
Pandas ofrece métodos específicos que facilitan el filtrado de datos basado en condiciones comunes, como .isin(), .between(), y .isnull().
# Filtrado de valores dentro de una lista
df_filtrado = df[df['columna'].isin([valor1, valor2])]
# Filtrado de valores dentro de un rango
df_filtrado = df[df['columna'].between(valor_min, valor_max)]
# Filtrado de valores nulos o no nulos
df_filtrado = df[df['columna'].isnull()]
df_no_nulos = df[df['columna'].notnull()]
Filtrado con Funciones Personalizadas
Para criterios de filtrado más complejos, puedes utilizar el método .apply() junto con una función personalizada.
df_filtrado = df[df['columna'].apply(lambda x: mi_funcion_personalizada(x))]
Combinación de Condiciones
Para filtros más complejos, puedes combinar múltiples condiciones usando operadores lógicos (& para AND, | para OR).
df_filtrado = df[(df['columna1'] > valor1) & (df['columna2'] < valor2)]
Estas técnicas de filtrado son esenciales para preparar y limpiar tus datos antes del análisis, permitiéndote enfocarte en los segmentos de datos más relevantes para tus necesidades de análisis.
Top
Data joining
“Data Joining” se refiere al proceso de combinar dos o más conjuntos de datos basándose en una columna común o índice para crear un único conjunto de datos integrado. Los métodos utilizados para el data joining en ciencia de datos se inspiran en gran medida en las operaciones de unión de bases de datos relacionales.
Pandas proporciona varios métodos para combinar y comparar Series o DataFrames.Los metodos para unir marcos de datos con Pandas son: append(), concat(), merge() o join(). El metodo compare() muestra las diferencias en valores entre dos Series o DataFrame.
concat(): fusiona varias Series o DataFrames a lo largo de un índice o columna compartido.df.join(): fusiona varios DataFrame a lo largo de las columnasdf.combine_first(): actualice los valores faltantes con valores no faltantes en la misma ubicaciónmerge(): Combina dos Series o DataFrames con unión estilo SQLcompare(): muestra las diferencias en valores entre dos Series o DataFrames.merge_ordered(): Combina dos Series o DataFrames a lo largo de un eje ordenadomerge_asof(): Combina dos Series o DataFrames con keys coincidentes cercanas en lugar de exactas
pd.concat()
Toma como entrada una lista, diccionario , Series o DataFrames y los une a lo largo de un eje específico:
Axis 0: Concatenación vertical (por defecto), donde los DataFrames o Series se apilan uno encima del otro. Esto es equivalente a añadir filas.Axis 1: Concatenación horizontal, donde los DataFrames o Series se unen lado a lado. Esto es equivalente a añadir columnas.
Lógica de Conjunto en los Índices
Una característica clave de concat() es su capacidad para manejar índices al concatenar:
- Unión (por defecto): Todos los índices únicos de cada objeto se incluyen en el índice del DataFrame resultante, lo que puede resultar en índices duplicados si estos no son únicos a través de los objetos concatenados.
- Intersección: Solo los índices compartidos por todos los objetos se incluyen en el DataFrame resultante, eliminando así cualquier índice que no esté presente en todos los objetos.
Manejo de Ejes no Concatenados
Para los ejes que no están siendo concatenados, puedes especificar cómo manejar los índices que no coinciden entre los objetos:
ignore_index=True:Ignora los índices de los objetos y crea un nuevo índice entero para el DataFrame resultante. Esto es útil cuando no te interesan los índices originales.keys=[...]: Permite especificar un conjunto de etiquetas para los objetos concatenados. Esto es útil para distinguir entre los datos de diferentes fuentes después de la concatenación, creando un MultiIndex.
# Concatenación vertical
result_vertical = pd.concat([df1, df2])
# Concatenación horizontal
result_horizontal = pd.concat([df1, df2], axis=1)
# Concatenación con intersección de índices
result_intersection = pd.concat([df1, df2], join='inner')
# Concatenación con un nuevo índice
result_ignore_index = pd.concat([df1, df2], ignore_index=True)
# Concatenación con claves específicas para cada DataFrame
result_keys = pd.concat([df1, df2], keys=['x', 'y'])
Al concatenar DataFramecon ejes con nombres, pandas intentará conservar estos nombres de índice/columna siempre que sea posible. En el caso de que todas las entradas compartan un nombre común, este nombre se asignará al resultado. Cuando los nombres de entrada no coinciden, el resultado no tendrá nombre.
pd.merge()
Realiza operaciones de unión similares a bases de datos relacionales como SQL. Los usuarios que estén familiarizados con SQL pero que sean nuevos en Pandas pueden hacer referencia a una comparación con SQL .
Tipos de fusión
Operaciones comunes de unión de estilo SQL.
uno a uno: unir dos DataFrames en sus índices que deben contener valores únicos.muchos a uno: unir un índice único a una o más columnas en un archivo DataFrame.muchos a muchos: unir columnas sobre columnas.
Nota
Al unir columnas sobre columnas, potencialmente una unión de muchos a muchos, se descartarán todos los índices de los objetos pasados del DataFrame.
Para una combinación de muchos a muchos, si una combinación de llaves aparece más de una vez en ambas tablas, el DataFrame resultante tendrá el producto cartesiano de los datos asociados.
result = pd.merge(df_left, df_right, on="key")
Claves en Uniones
El argumento how de merge() especifica qué claves se incluyen en la tabla resultante. Si una combinación de keys no aparece en las tablas izquierda o derecha, los valores en la tabla unida serán NA. A continuación se muestra un resumen de las opciones y sus nombres equivalentes en SQL:
| Nombre de unión | SQL | Descripción |
|---|---|---|
| left | LEFT OUTER JOIN | Utilice únicamente las teclas del marco izquierdo |
| right | RIGHT OUTER JOIN | Utilice únicamente las teclas del marco derecho |
| outer | FULL OUTER JOIN | Utilice la unión de claves de ambos marcos. |
| inner | INNER JOIN | Utilice la intersección de claves de ambos fotogramas. |
| cross | CROSS JOIN | Crea el producto cartesiano de filas de ambos marcos. |
-
left: Utiliza las claves del marco (DataFrame o tabla) izquierdo para encontrar coincidencias en el marco derecho. Si no hay coincidencias en el derecho para una clave del izquierdo, aún se incluirán las filas del izquierdo, rellenando las columnas del derecho con NULL. -
right: Opera de manera inversa al LEFT JOIN, utilizando las claves del marco derecho para encontrar coincidencias en el marco izquierdo. Las filas del derecho sin coincidencias en el izquierdo se incluirán, con NULL en las columnas del izquierdo. -
outer: Combina las estrategias de LEFT y RIGHT JOIN, utilizando las claves de ambos marcos para la unión. Incluirá todas las filas de ambos marcos, rellenando con NULL las columnas del marco opuesto cuando no haya coincidencias. -
inner: Utiliza la intersección de las claves de ambos marcos, es decir, solo incluye las filas con claves que tienen coincidencias en ambos marcos. Las filas sin coincidencias en cualquiera de los marcos se excluyen del resultado final. -
cross: No se basa en claves para realizar la unión. En lugar de eso, crea un producto cartesiano, combinando cada fila del marco izquierdo con cada fila del marco derecho, resultando en un número de filas igual al producto del número de filas de ambos marcos.
Integridad de los datos al realizar operaciones de fusión
El argumento validate permite al usuario especificar la expectativa sobre la relación entre las claves de unión en los DataFrames que se están combinando, ayudando a identificar problemas de datos antes de que la fusión se complete. Acepta una de las siguientes cadenas, cada una representando un tipo específico de relación entre las claves de los DataFrames a fusionar:
1:1: Verifica que las claves sean únicas tanto en el DataFrame izquierdo como en el derecho. Esto asegura que cada clave se utiliza exactamente una vez en cada DataFrame. Es útil cuando quieres garantizar que no hay duplicados en ninguna de las tablas antes de la fusión.1:m o m:1: Verifica que todas las claves en el DataFrame del lado ‘1’ sean únicas, pero permite duplicados en el lado ‘m’. Esto es común en situaciones donde un DataFrame tiene una clave primaria y el otro tiene una clave foránea que puede repetirse.m:m: Permite duplicados en ambos DataFrames. Aunque este es el comportamiento predeterminado si no se especifica validate, utilizar este argumento explícitamente puede ser útil para documentar la naturaleza de la fusión y garantizar que la operación es intencional.
df.join()
El método .join() permite unir DataFrames basándose en sus índices o en una clave (columna) común. Por defecto, realiza una unión izquierda (left join), manteniendo todas las filas del DataFrame sobre el cual se llama el método e incorporando las columnas del DataFrame pasado como argumento.
df1.join(df2)
En este ejemplo, df1 es el DataFrame “izquierdo” al cual se unirán las columnas de df2 basándose en los índices de ambos DataFrames.
Parámetros Importantes
other: Otro DataFrame o Serie o lista de DataFrames con los cuales se unirá el DataFrame original.on: Especifica la columna del DataFrame desde el cual se llama.join()que se utilizará como clave para la unión. Si se especifica, esta columna debe existir en el DataFrame “izquierdo”.how: Define cómo se realiza la unión: ‘left’ (por defecto), ‘right’, ‘inner’, ‘outer’.lsuffix,rsuffix: Sufijos a agregar a las columnas con el mismo nombre en ambos DataFrames para diferenciarlas en el DataFrame resultante.
df.combine.first()
Actualice los valores faltantes de uno DataFrame con los valores no faltantes en otro DataFrameen la ubicación correspondiente. Es decir, se puede utilizar para rellenar valores faltantes en un DataFrame con valores de otro DataFrame. La idea es que, para cualquier elemento en el DataFrame original que sea NA (no disponible o NaN), si hay un valor correspondiente en el mismo lugar del otro DataFrame, este valor se usará para rellenar el NA en el DataFrame original. Si no hay NA, el valor del DataFrame original se mantiene. Este método no modifica ninguno de los DataFrames originales; en su lugar, crea un nuevo DataFrame como resultado.
df1.combine_first(df2)
En este caso, df1 es el DataFrame principal cuyos valores NA se buscan rellenar con los valores de df2. Los índices y columnas de ambos DataFrames juegan un papel crucial aquí: combine_first intentará hacer la coincidencia basándose en estos índices y columnas. Si df2 tiene valores en posiciones donde df1 tiene NA, estos valores de df2 se utilizan en el DataFrame resultante.
.compare()
Comparar dos DataFrameo Series, respectivamente, y resumir sus diferencias. De forma predeterminada, si dos valores correspondientes son iguales, se mostrarán como NaN. Además, si todos los valores están en una fila/columna completa, la fila/columna se omitirá del resultado. Las diferencias restantes se alinearán en columnas.
df1.compare(df2)