Analisis de Series Temporales
Los datos de series de tiempo incluyen marcas de tiempo y, a menudo, se generan mientras se monitorea el proceso industrial o se rastrea cualquier métrica comercial. Una secuencia ordenada de valores de marca de tiempo a intervalos igualmente espaciados se denomina serie de tiempo . El análisis de dichas series temporales se utiliza en muchas aplicaciones, como pronósticos de ventas, estudios de servicios públicos, análisis presupuestario, pronósticos económicos, estudios de inventario, etc. Existe una gran cantidad de métodos que se pueden utilizar para modelar y pronosticar series de tiempo.
Comprender el conjunto de datos de series temporales
La pregunta más esencial sería: ¿qué entendemos por datos de series temporales? Por supuesto, hemos oído hablar de ello en varias ocasiones. ¿Quizás podamos definirlo? Seguro que podemos. Básicamente, una serie de tiempo es una colección de observaciones realizadas de forma secuencial en el tiempo. Tenga en cuenta que aquí hay dos frases clave importantes: una colección de observaciones y secuencialmente en el tiempo. Como es una serie, tiene que ser una colección de observaciones y, como trata con el tiempo, tiene que hacerlo de forma secuencial.
Tomemos un ejemplo de datos de series de tiempo: 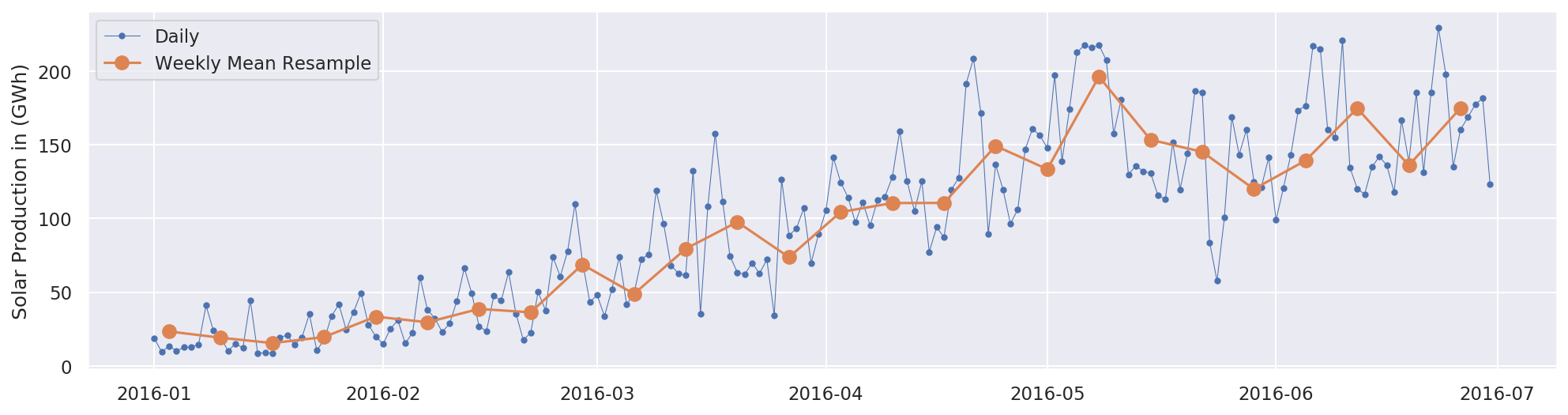
La captura de pantalla anterior ilustra la producción de energía solar (medida en gigavatios hora ( GWh )) durante los primeros seis meses de 2016. También muestra el consumo de electricidad tanto a diario como a semana.
Fundamentos de la TSA
Para comprender el conjunto de datos de series temporales, generemos aleatoriamente un conjunto de datos normalizado:
Podemos utilizar numpy para generar conjuntos de datos aleatorios:
zero_mean_series = np.random.normal(loc=0.0, scale=1., size=50)
Podemos realizar una suma acumulativa sobre la lista anterior:
random_walk = np.cumsum(zero_mean_series)
random_walk
Serie temporal univariada
Cuando capturamos una secuencia de observaciones para la misma variable durante un período de tiempo particular, la serie se denomina serie de tiempo univariada. En general, en una serie temporal univariante, las observaciones se toman durante períodos de tiempo regulares, como el cambio de temperatura a lo largo del tiempo a lo largo de un día.
Características de los datos de series temporales.
Cuando se trabaja con datos de series temporales, se pueden observar varias características únicas. En general, las series temporales tienden a presentar las siguientes características:
- Al observar datos de series temporales, es fundamental ver si hay alguna tendencia . Observar una tendencia significa que los valores de medición promedio parecen disminuir o aumentar con el tiempo.
- Los datos de series temporales pueden contener una cantidad notable de valores atípicos . Estos valores atípicos se pueden observar cuando se representan en un gráfico.
- Algunos datos de series temporales tienden a repetirse durante un determinado intervalo en algunos patrones. Nos referimos a estos patrones repetitivos como estacionalidad .
- A veces, hay un cambio desigual en los datos de las series temporales. Nos referimos a estos cambios desiguales como cambios abruptos . Observar cambios abruptos en las series temporales es esencial ya que revela fenómenos subyacentes esenciales.
- Algunas series tienden a seguir una variación constante a lo largo del tiempo. Por lo tanto, es esencial observar los datos de las series de tiempo y ver si los datos exhiben una variación constante a lo largo del tiempo.
Trabajo con Series Temporales
Open Power System Data para comprender la TSA Jupyter Noteboook:
Convertir Date en el Indice del Dataframe:
Cambiar el índice de tu DataFrame a la columna “Date” significa que utilizarás los valores de esta columna como índices de las filas en lugar de los índices numéricos predeterminados de Pandas. Esto es especialmente útil cuando estás trabajando con series temporales, ya que facilita el acceso y la manipulación de los datos basados en fechas específicas:
Como resultado de esta accion:
- Acceso basado en fecha: Puedes acceder a las filas utilizando valores de fecha directamente. Por ejemplo,
df.loc['2023-03-15']te daría los datos para el 15 de marzo de 2023. - Operaciones de series temporales: Facilita realizar operaciones específicas de series temporales, como re-muestreo (
resample), interpolaciones y desplazamientos de tiempo (shift), entre otros. - Visualización: Al hacer gráficos, Pandas automáticamente reconocerá que el índice es una serie temporal, lo cual puede hacer que la generación de gráficos de series de tiempo sea más directa y con etiquetas de fecha bien formateadas.
Puede hacerse con el codigo:
df.set_index('Date', inplace=True)
Indexación basada en el tiempo
La indexación basada en el tiempo es un método muy poderoso de la biblioteca pandas cuando se trata de datos de series de tiempo. Tener una indexación basada en el tiempo permite utilizar una cadena formateada para seleccionar datos.
Vea el siguiente código, por ejemplo:
# seleccionar datos de un año
df_power.loc['2015']
# Seleccionar datos de un mes
df_power.loc['2015-10']
# seleccionar datos de un dia
df_power.loc['2015-10-02']
# O una serie personalizada
df.loc['2017-01-01':'2017-02-15']
Tenga en cuenta que utilizamos el descriptor de acceso loc del marco de datos pandas. En el ejemplo anterior, utilizamos una fecha como cadena para seleccionar una fila. Podemos usar todo tipo de técnicas para acceder a filas tal como lo podemos hacer con un índice de marco de datos normal.
Ejemplo.