Discusión del análisis multivariado utilizando el conjunto de datos del Titanic
El 15 de abril de 1912, el barco de pasajeros más grande jamás construido hasta entonces chocó con un iceberg durante su viaje inaugural. Cuando el Titanic se hundió, murieron 1.502 de los 2.224 pasajeros y tripulantes. El archivo ( https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv ) contiene datos de 887 pasajeros reales del Titanic. Cada fila representa una persona. Las columnas describen diferentes atributos sobre la persona en el barco donde la columna es una identificación única del pasajero, es el número que sobrevivió (1) o murió (0), es la clase del pasajero (es decir, primera, segunda o tercera ), es el nombre del pasajero, es el sexo del pasajero, es la edad del pasajero, es el número de hermanos/cónyuges a bordo del Titanic, es el número de padres/hijos a bordo del Titanic, es el número de billete, es la tarifa de cada billete , es el número de cabina y es donde el pasajero subió al barco (por ejemplo: C se refiere a Cherburgo, S se refiere a Southampton y Q se refiere a Queenstown).
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('titanic.csv')
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
# No. de filas y columnas del dataframe
df.shape
(891, 12)
mising_values = df.isnull().sum().sort_values(ascending=False)
mising_values
Cabin 687
Age 177
Embarked 2
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
SibSp 0
Parch 0
Ticket 0
Fare 0
dtype: int64
Todos los registros parecen estar bien excepto Embarked, Age y Cabin. La variable Cabin requiere más investigación para completar tantas, pero no la usemos en nuestro análisis porque falta el 77%. Además, será bastante complicado lidiar con la variable Age, a la que le faltan 177 valores. No podemos ignorar el factor edad porque podría correlacionarse con la tasa de supervivencia. A la variable Embarked solo le faltan dos valores, que se pueden completar fácilmente.
Dado que las columnas PassengerId, Ticket y Name tienen valores únicos, no se correlacionan con una alta tasa de supervivencia.
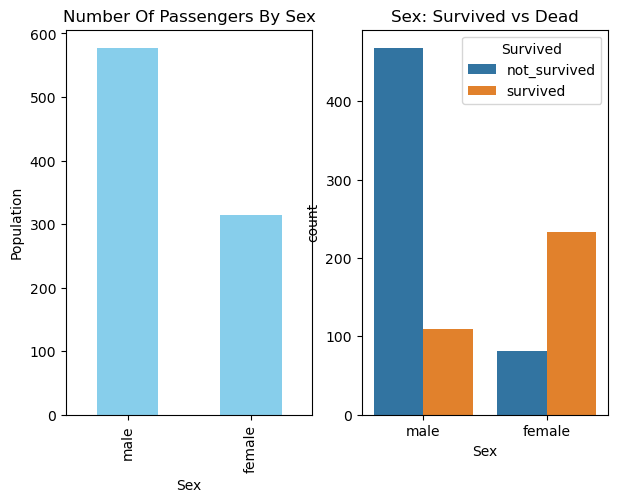
Primero, conozcamos los porcentajes de mujeres y hombres que sobrevivieron al desastre:
women = df.loc[df.Sex == 'female']['Survived']
rate_women = round(sum(women)/len(women), 2)
#percentage of men survived
men = df.loc[df.Sex == 'male']["Survived"]
rate_men = round(sum(men)/len(men), 2)
print(str(rate_women) +" % of women who survived." )
print(str(rate_men) + " % of men who survived." )
0.74 % of women who survived.
0.19 % of men who survived.
Puedes ver que el número de mujeres que sobrevivieron fue alto, por lo que el género podría ser el atributo que contribuye al análisis de la supervivencia de cualquier variable (persona). Visualicemos esta información sobre los números de supervivencia en hombres y mujeres
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
df['Survived'] = df['Survived'].map({0:"not_survived", 1:"survived"})
fig, ax = plt.subplots(1, 2, figsize = (7, 5))
df["Sex"].value_counts().plot.bar(color = "skyblue", ax = ax[0])
ax[0].set_title("Number Of Passengers By Sex")
ax[0].set_ylabel("Population")
sns.countplot(x="Sex", hue="Survived", data=df, ax=ax[1])
ax[1].set_title("Sex: Survived vs Dead")
plt.show()
Veamos los sobrevivientes por cada clase
fig, ax = plt.subplots(1, 2, figsize = (7, 5))
df["Pclass"].value_counts().plot.bar(color = "skyblue", ax = ax[0])
ax[0].set_title("Number Of Passengers By Pclass")
ax[0].set_ylabel("Population")
sns.countplot(x = "Pclass", hue = "Survived", data = df, ax = ax[1])
ax[1].set_title("Pclass: Survived vs Dead")
plt.show()
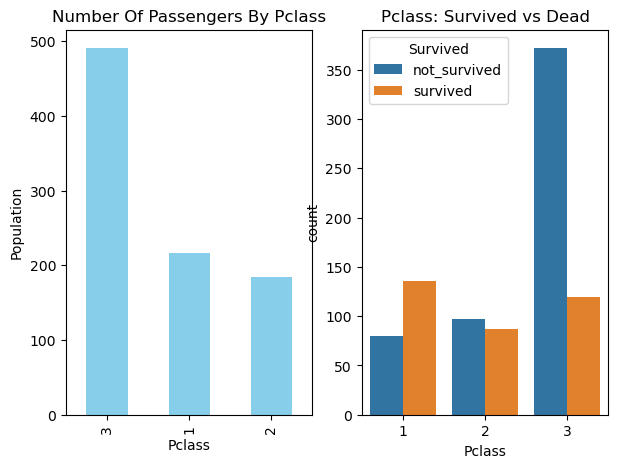
Parece que el número de pasajeros en la clase Pclass 3 era alto y la mayoría de ellos no pudo sobrevivir. En la clase de muerte Pclass el número de muertes es alto. Y en Pclass 1 la mayoría de los pasajeros sobrevivieron.
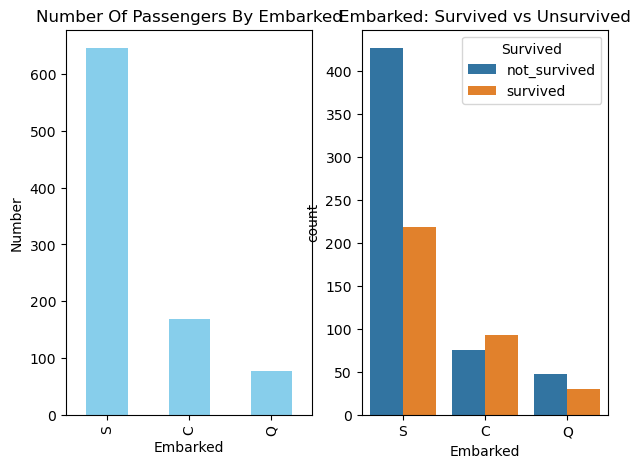
df["Embarked"] = df["Embarked"].fillna("S")
df
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | not_survived | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | survived | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | survived | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | survived | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | not_survived | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | not_survived | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | survived | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | not_survived | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 889 | 890 | survived | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | not_survived | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 12 columns
fig, ax = plt.subplots(1, 2, figsize = (7, 5))
df["Embarked"].value_counts().plot.bar(color = "skyblue", ax = ax[0])
ax[0].set_title("Number Of Passengers By Embarked")
ax[0].set_ylabel("Number")
sns.countplot(x = "Embarked", hue = "Survived", data = df, ax = ax[1])
ax[1].set_title("Embarked: Survived vs Unsurvived")
plt.show()
sns.displot(df['Age'].dropna(), kde=True)
C:\Users\ferna\anaconda3\Lib\site-packages\seaborn\axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)
<seaborn.axisgrid.FacetGrid at 0x17407c52810>
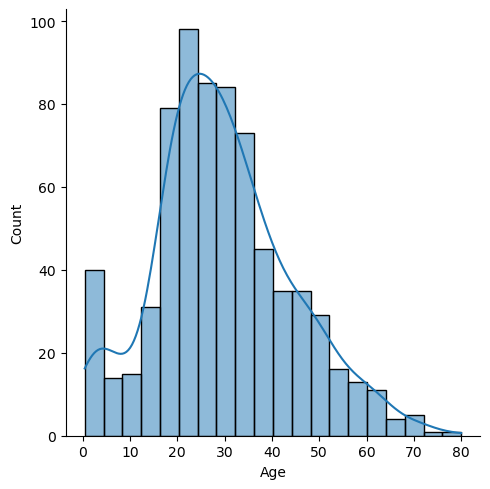
Ahora, realicemos el primer análisis multivariado en el conjunto de datos del Titanic con las variables
sns.set(style="ticks", color_codes=True)
sns.pairplot(df,height=3,vars = [ 'Fare','Age','Pclass'], hue="Survived")
plt.show()
C:\Users\ferna\anaconda3\Lib\site-packages\seaborn\axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)
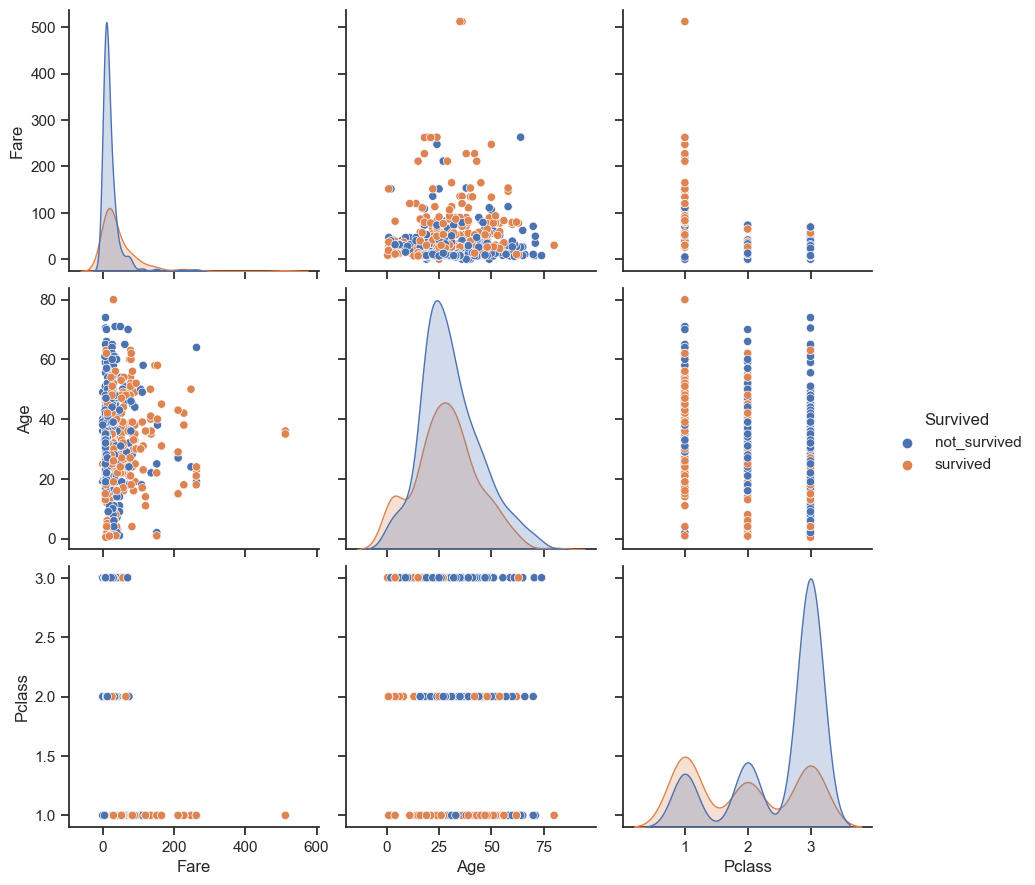
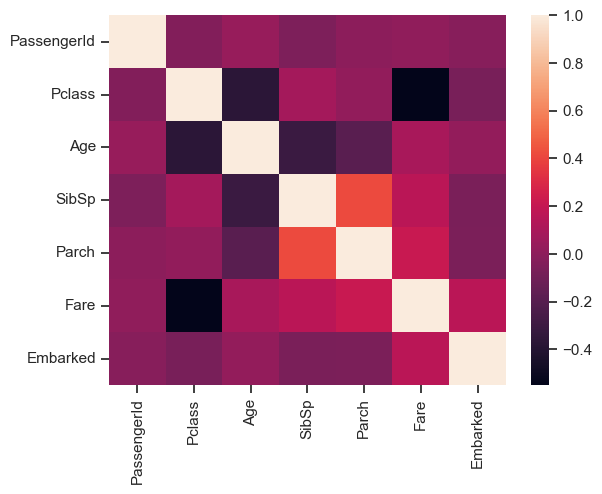
Ahora veamos la tabla de correlación con un mapa de calor. Pero primero mapeemos los registros de Embarque con valores enteros para que también podamos incluir Embarque en nuestro análisis de correlación.
df['Embarked'] = df['Embarked'].map({"S":1, "C":2,"Q":2,"NaN":0})
Tcorrelation = df.corr(method='pearson', numeric_only = True)
Tcorrelation
| PassengerId | Pclass | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|
| PassengerId | 1.000000 | -0.035144 | 0.036847 | -0.057527 | -0.001652 | 0.012658 | -0.022204 |
| Pclass | -0.035144 | 1.000000 | -0.369226 | 0.083081 | 0.018443 | -0.549500 | -0.074053 |
| Age | 0.036847 | -0.369226 | 1.000000 | -0.308247 | -0.189119 | 0.096067 | 0.023233 |
| SibSp | -0.057527 | 0.083081 | -0.308247 | 1.000000 | 0.414838 | 0.159651 | -0.068734 |
| Parch | -0.001652 | 0.018443 | -0.189119 | 0.414838 | 1.000000 | 0.216225 | -0.060814 |
| Fare | 0.012658 | -0.549500 | 0.096067 | 0.159651 | 0.216225 | 1.000000 | 0.162184 |
| Embarked | -0.022204 | -0.074053 | 0.023233 | -0.068734 | -0.060814 | 0.162184 | 1.000000 |
sns.heatmap(Tcorrelation,xticklabels=Tcorrelation.columns,
yticklabels=Tcorrelation.columns)
<Axes: >