Ayudas visuales para EDA
Presentar resultados a las partes interesadas es muy complejo en el sentido de que nuestra audiencia puede no tener suficientes conocimientos técnicos para comprender la jerga de programación y otros tecnicismos. Por tanto, las ayudas visuales son herramientas muy útiles. En este capítulo, nos centraremos en diferentes tipos de ayudas visuales que se pueden utilizar con nuestros conjuntos de datos.
- Line chart (Gráfico de Líneas)
- Bar chart (Gráfico de Barras)
- Scatter plot (Gráfico de Dispersión)
- Area plot and stacked plot (Parcela de área y parcela apilada)
- Pie chart (Gráfico Circular)
- Table chart (Gráfico de Tabla)
- Polar chart (Gráfico de Radar o Polar)
- Histogram (Histograma)
- Lollipop chart (Gráfico de Piruletas)
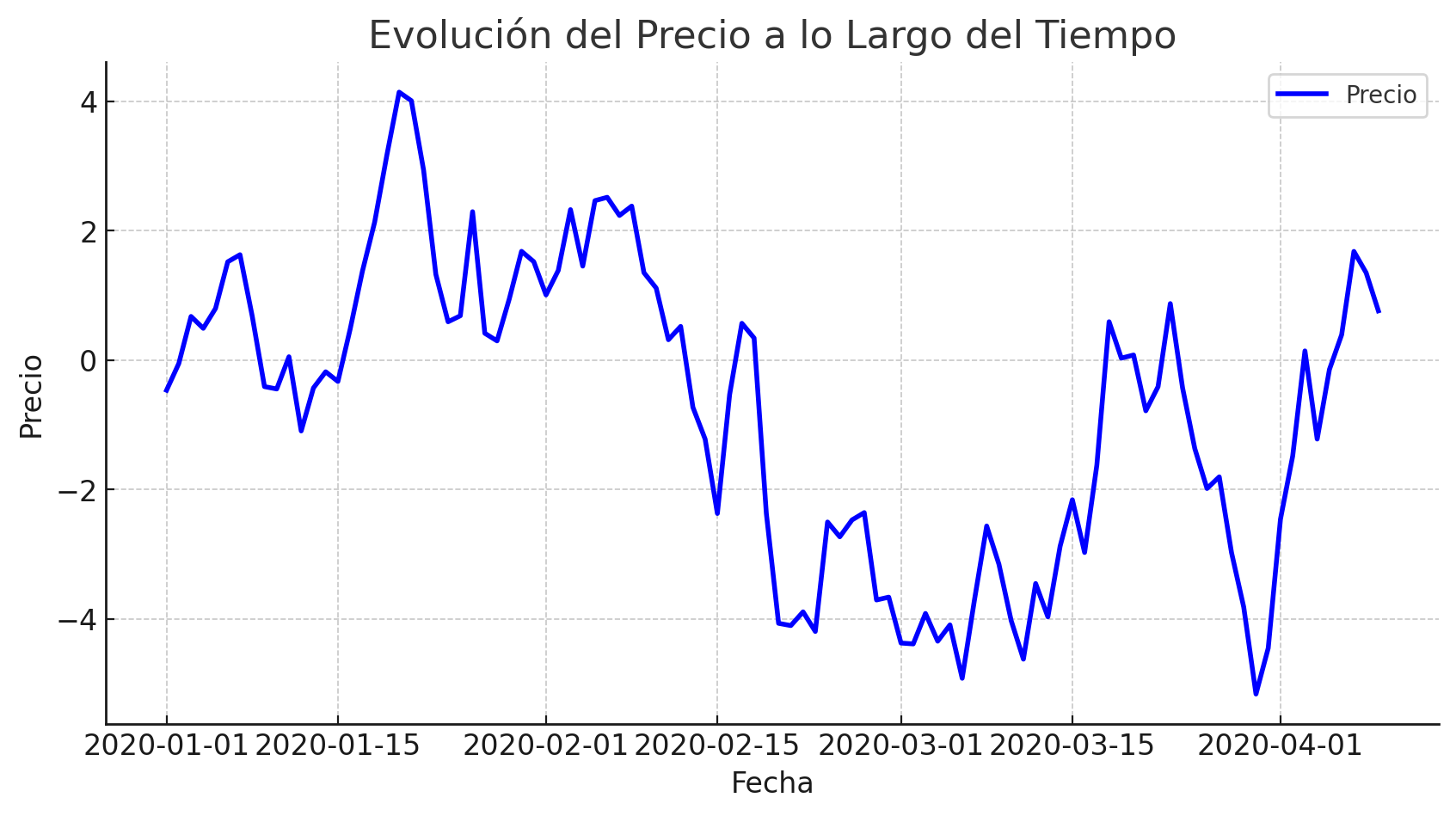
Line chart (Gráfico de Líneas)
Se utiliza un gráfico de líneas para ilustrar la relación entre dos o más variables continuas. Estas pueden ser por ejemplo fechas y precios.
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
plt.plot(df['Fecha'], df['Precio'], marker='', color='blue', linewidth=2, label="Precio")
plt.title('Evolución del Precio a lo Largo del Tiempo')
plt.xlabel('Fecha')
plt.ylabel('Precio')
plt.legend()
plt.show()
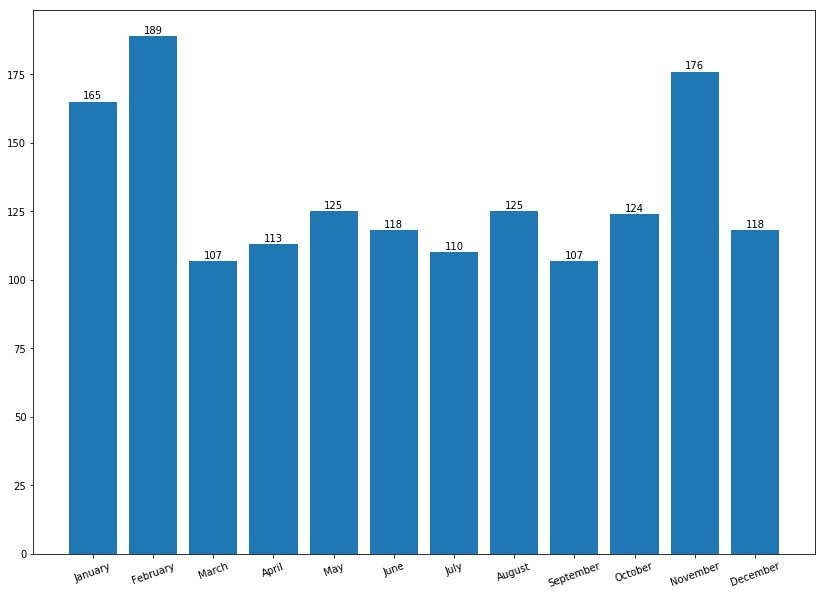
Bar chart (Gráfico de Barras)
Las barras se pueden dibujar horizontal o verticalmente para representar variables categóricas. se utilizan con frecuencia para distinguir objetos entre distintas colecciones con el fin de realizar un seguimiento de las variaciones a lo largo del tiempo.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6)) # Cambia el tamaño según tus necesidades
plt.bar(months, values, color='blue') # Usa el color que prefieras
# Añadir valores en la parte superior de las barras
for i, value in enumerate(values):
plt.text(i, value + 3, str(value), ha='center')
# Etiquetas y título
plt.xlabel('Month')
plt.ylabel('Value') # Reemplaza 'Value' con la variable correspondiente
plt.title('Monthly Values') # Reemplaza 'Monthly Values' con un título apropiado
plt.xticks(rotation=45) # Rota las etiquetas si es necesario
plt.tight_layout() # Ajusta automáticamente los parámetros de la subtrama
# Muestra el gráfico
plt.show()
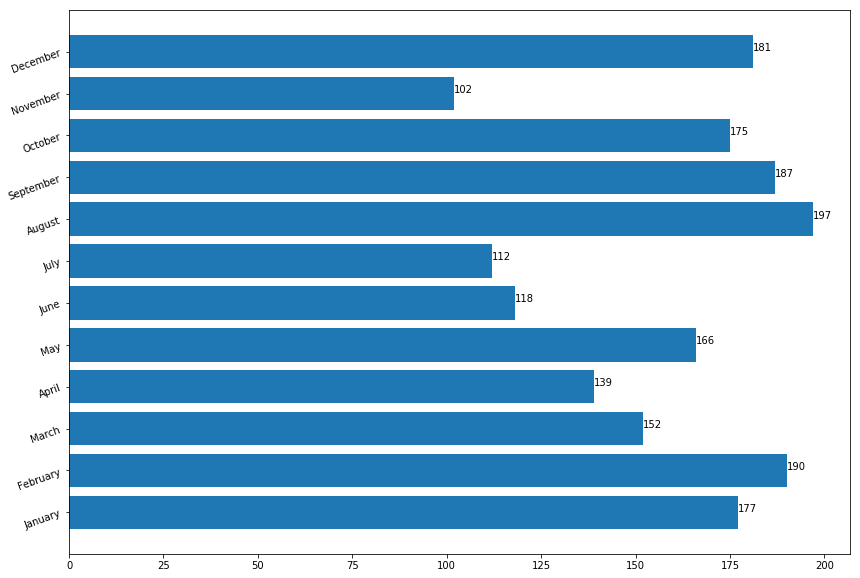
Para crear un grafico de barras horizontales se mantiene el codigo, exepto plt.xticks lo cambiamos por plt.yticks() y plt.bar() los cambiamos por plt.barh().
Scatter plot (Gráfico de Dispersión)
Los diagramas de dispersión también se denominan gráficos de dispersión, scatter graphs, scatter charts, scattergrams, and scatter diagrams. Utilizan un sistema de coordenadas cartesianas para mostrar valores de normalmente dos variables para un conjunto de datos.
¿Cuándo deberíamos utilizar un diagrama de dispersión? Los diagramas de dispersión se pueden construir en las dos situaciones siguientes:
- Cuando una variable continua depende de otra variable, que está bajo el control del observador.
- Cuando ambas variables continuas son independientes
Los diagramas de dispersión se utilizan cuando necesitamos mostrar la relación entre dos variables y, por lo tanto, a veces se los denomina diagramas de correlación.
Algunos ejemplos en los que los diagramas de dispersión son adecuados son los siguientes:
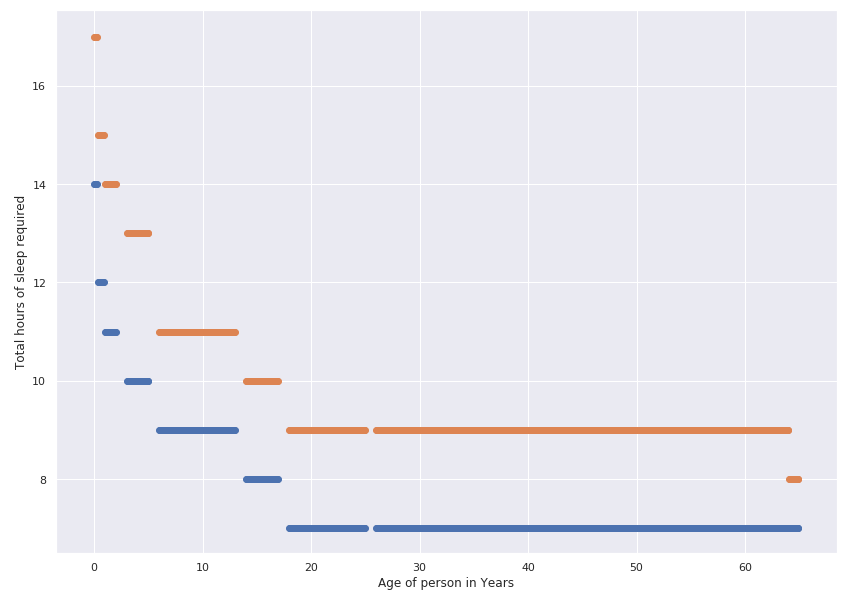
- Los estudios de investigación han establecido con éxito que la cantidad de horas de sueño que necesita una persona depende de su edad.
- El ingreso promedio de los adultos se basa en el número de años de educación.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set()
# Un diagrama de dispersión normal
plt.scatter(x=sleepDf["age"]/12., y=sleepDf["min_recommended"])
plt.scatter(x =sleepDf["edad"]/12., y=sleepDf['max_recommended'])
plt.xlabel('Edad de la persona en años')
plt.ylabel('Total de horas de sueño requeridas')
plt.show()
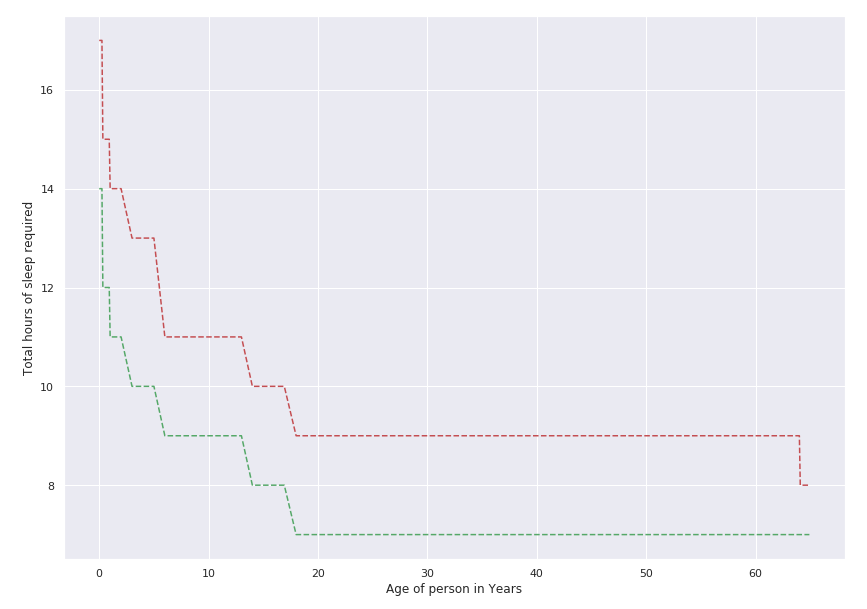
Un gráfico de líneas de los mismos datos es el siguiente:
plt.plot(sleepDf['age']/12., sleepDf['min_recommended'], 'g--')
plt.plot(sleepDf['age']/12., sleepDf['max_recommended'] , 'r--')
plt.xlabel('Edad de la persona en años')
plt.ylabel('Total de horas de sueño requeridas')
plt.show()
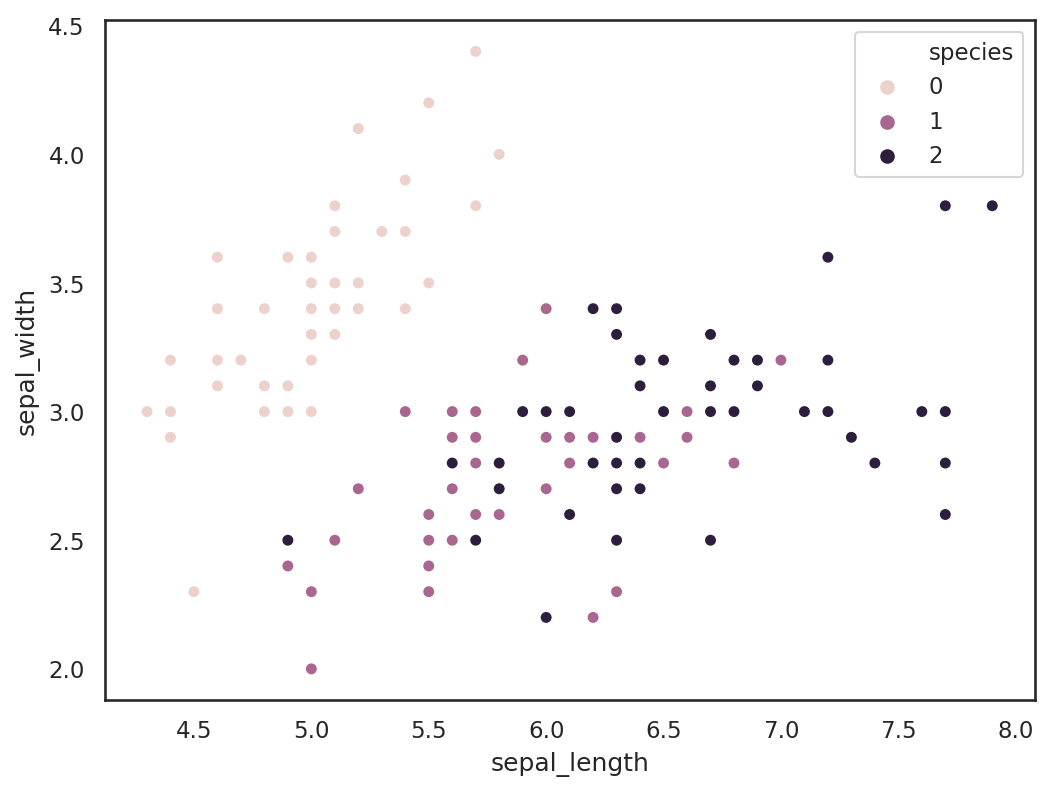
Otro ejemplo de un diagrama de dispersion que utiliza el conjunto de datos más popular utilizado en la ciencia de datos: el conjunto de datos Iris.
El conjunto de datos contiene 50 ejemplos de cada una de tres especies diferentes de Iris, denominadas setosa, virginica y versicolor. Cada ejemplo tiene cuatro atributos diferentes: petal_length, petal_width, sepal_lengthy sepal_width
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (8, 6)
plt.rcParams['figure.dpi'] = 150
# Utilice el estilo de seaborn
sns.set()
# Cargue el conjunto de datos de Iris
df = sns.load_dataset('iris')
df['species'] = df['species'].map({'setosa': 0, "versicolor": 1, "virginica": 2})
# Crea un diagrama de dispersión regular
plt.scatter(x=df["sepal_length"], y=df["sepal_width"], c = df.species)
# Crea las etiquetas para los ejes y muestra el grafico
plt.xlabel('Septal Length')
plt.ylabel('Petal length')
plt.show()
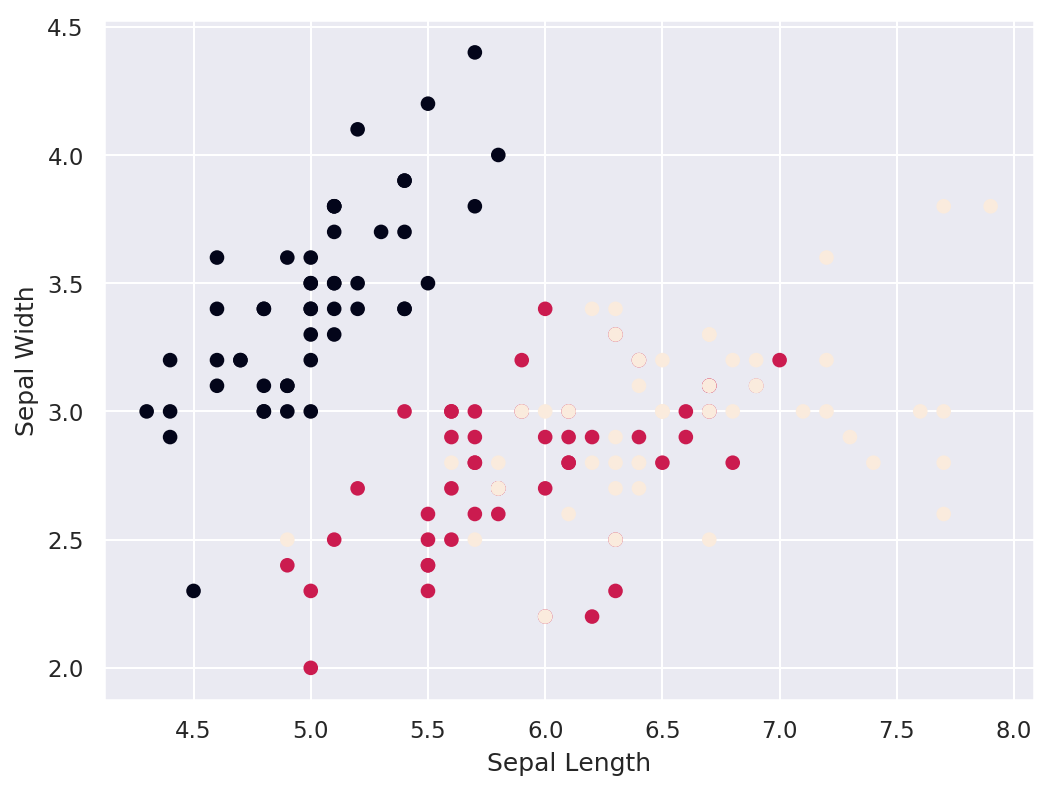
Grafico de Burbujas
Un diagrama de burbujas es una manifestación del diagrama de dispersión en el que cada punto de datos del gráfico se muestra como una burbuja. Cada burbuja se puede ilustrar con un color, tamaño y apariencia diferente.
# Load the Iris dataset
df = sns.load_dataset('iris')
df['species'] = df['species'].map({'setosa': 0, "versicolor": 1, "virginica": 2})
# Create bubble plot
plt.scatter(df.petal_length, df.petal_width,
s=50*df.petal_length*df.petal_width,
c=df.species,
alpha=0.3
)
# Create labels for axises
plt.xlabel('Septal Length')
plt.ylabel('Petal length')
plt.show()
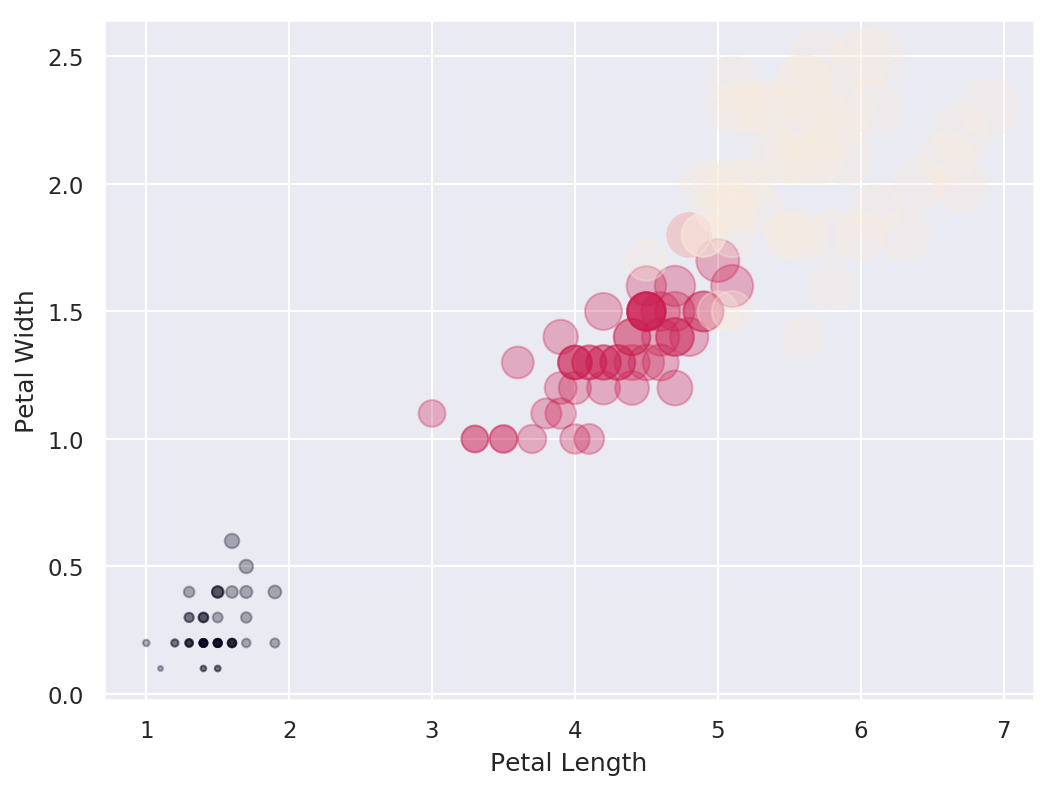
Diagrama de dispersión usando seaborn
También se puede generar un diagrama de dispersión utilizando la biblioteca seaborn. Seaborn mejora visualmente el gráfico. Podemos ilustrar la relación entre x e y para distintos subconjuntos de datos utilizando los parámetros size, style y hue del diagrama de dispersión en seaborn.
df = sns.load_dataset('iris')
df['species'] = df['species'].map({'setosa': 0, "versicolor": 1, "virginica": 2})
sns.scatterplot(x=df["sepal_length"], y=df["sepal_width"], hue=df.species, data=df)
Area plot and stacked plot
El gráfico apilado debe su nombre al hecho de que representa el área bajo un gráfico lineal y que varios de estos gráficos se pueden apilar uno encima del otro, dando la sensación de una pila. El gráfico apilado puede resultar útil cuando queremos visualizar el efecto acumulativo de múltiples variables numericas que se trazan en el eje y.
Para simplificar esto, piense en un gráfico de área como un gráfico de líneas que muestra el área cubierta rellenándola con un color.
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
months= [x for x in range(1,13)]
# Create placeholders for plot and add required color
plt.plot([],[], color='sandybrown', label='houseLoanMortgage')
plt.plot([],[], color='tan', label='utilitiesBills')
plt.plot([],[], color='bisque', label='transportation')
plt.plot([],[], color='darkcyan', label='carMortgage')
# Add stacks to the plot
plt.stackplot(months, houseLoanMortgage, utilitiesBills, transportation, carMortgage, colors=['sandybrown', 'tan', 'bisque', 'darkcyan'])
plt.legend()
# Add Labels
plt.title('Household Expenses')
plt.xlabel('Months of the year')
plt.ylabel('Cost')
# Display on the screen
plt.show()
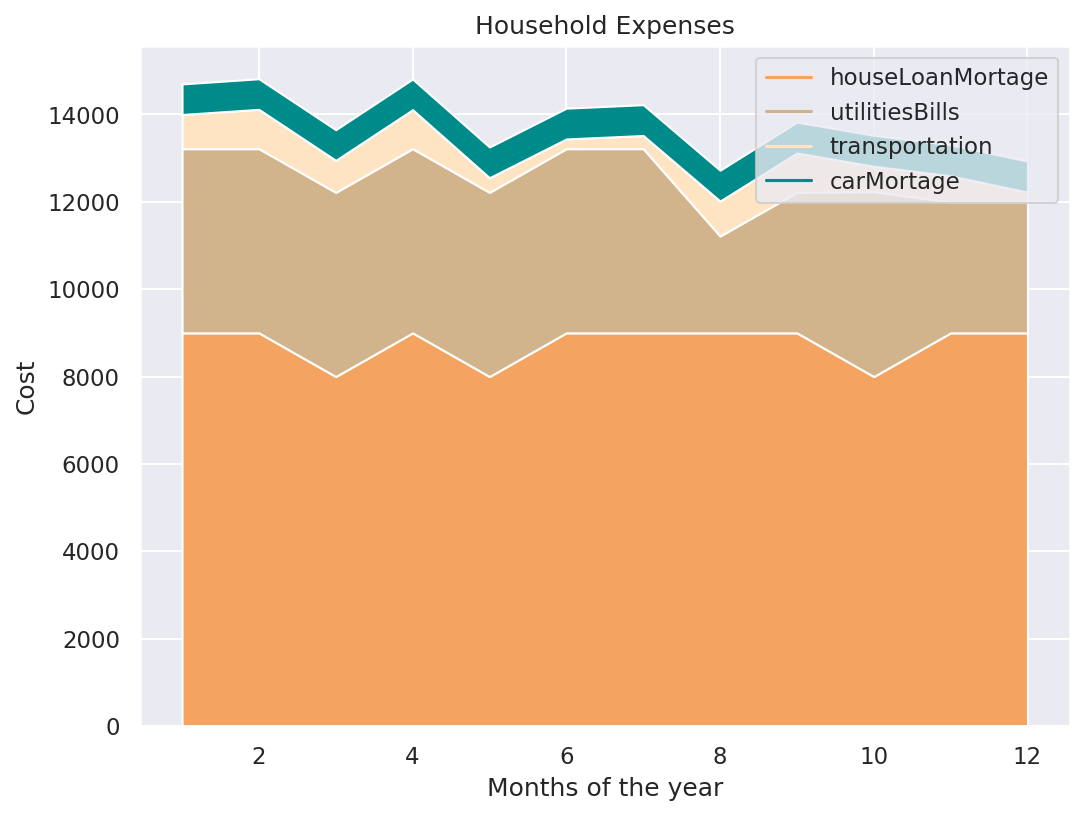
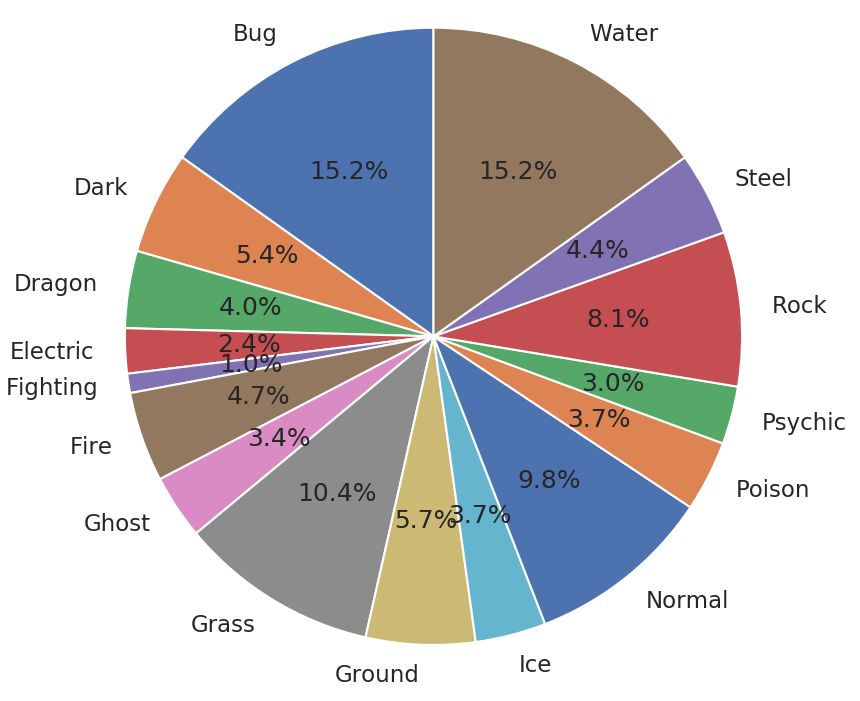
Grafico Circular (Pie Chart)
El propósito del gráfico circular es comunicar proporciones. En este ejemplo usamos un dataframe de un stock.
import matplotlib.pyplot as plt
plt.pie(pokemon['amount'], labels=pokemon.index, shadow=False, startangle=90, autopct='%1.1f%%',)
plt.axis('equal')
plt.show()
Se puede uutilizar pandas directamente para generar un grafico circular:
pokemon.plot.pie(y="amount", figsize=(20, 10))
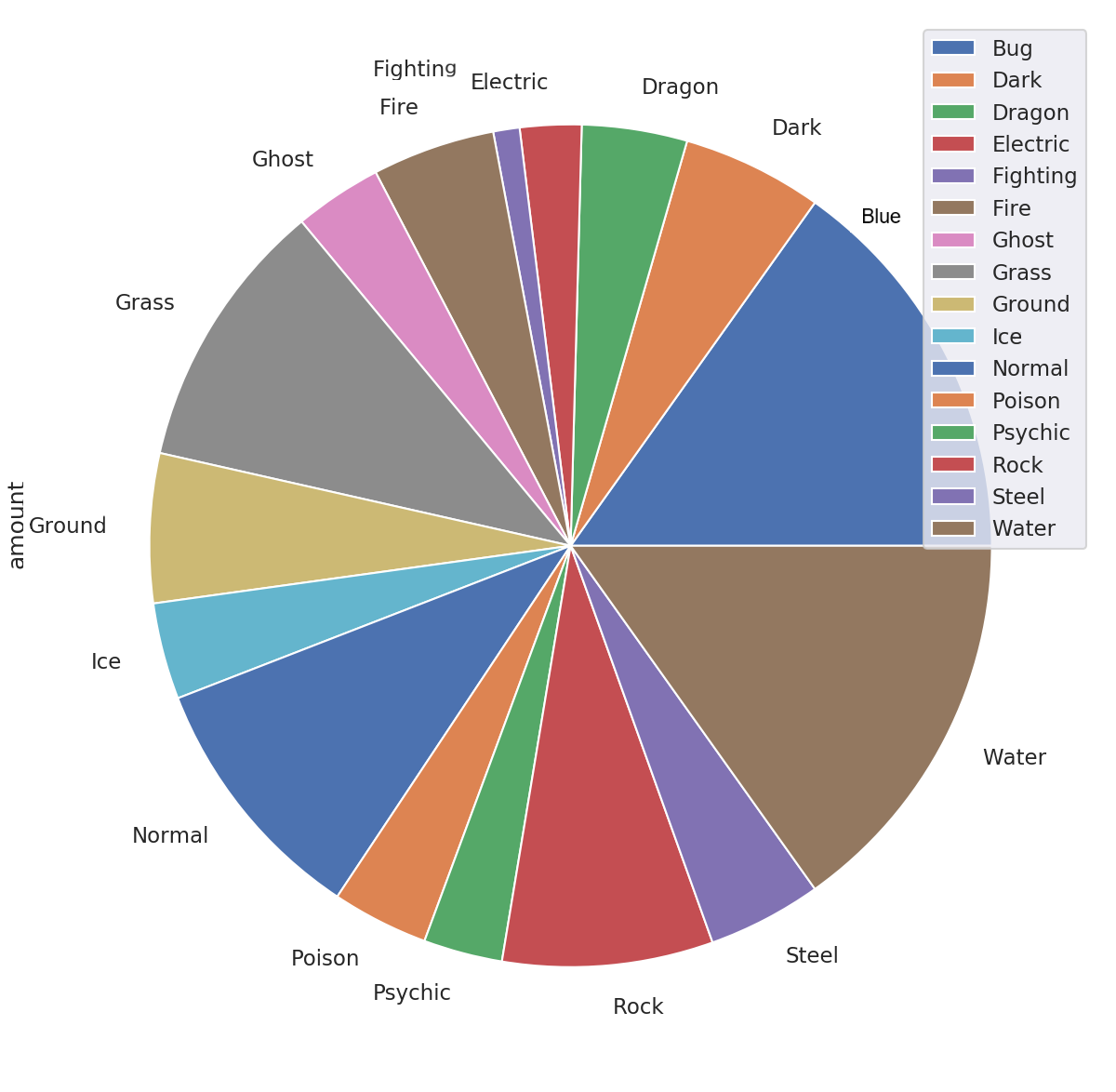
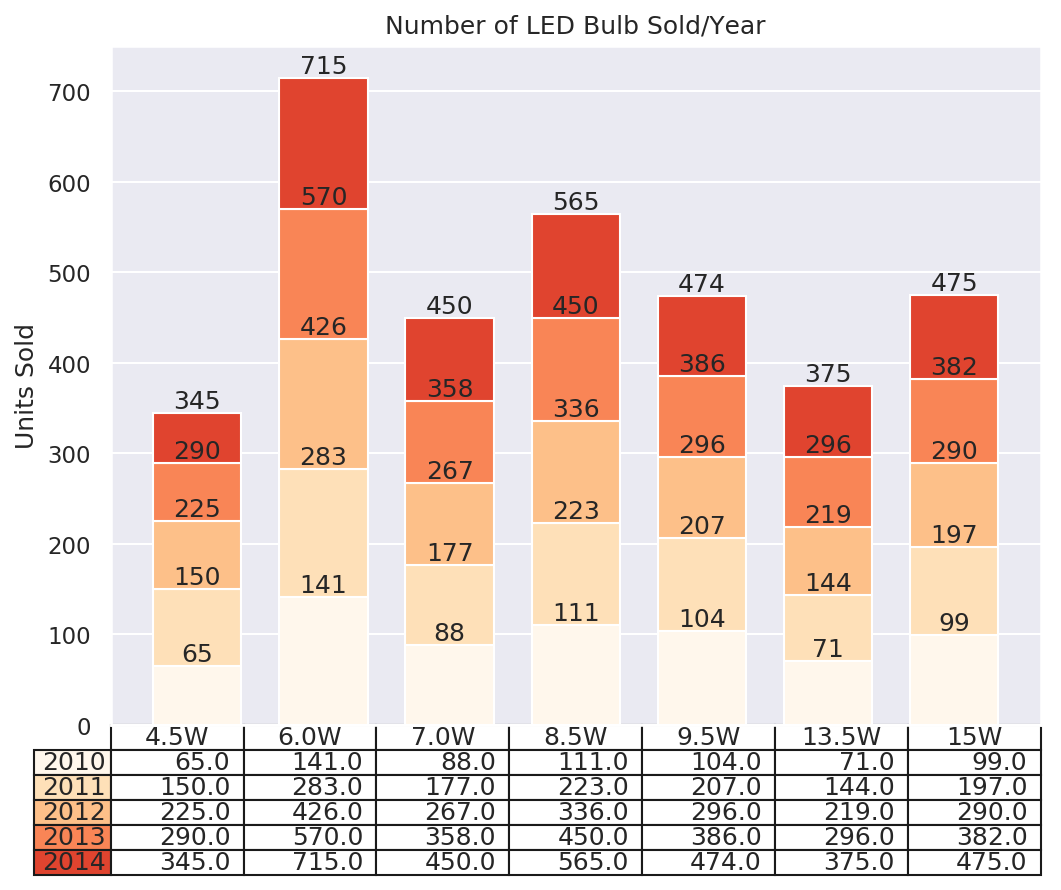
Grafico de Tablas (table chart)
Un gráfico de tabla combina un gráfico de barras y una tabla. Para comprender el gráfico de la tabla, consideremos el siguiente conjunto de datos.
Considere las bombillas LED estándar que vienen en diferentes potencias. La bombilla LED estándar de Philips puede ser de 4,5 vatios, 6 vatios, 7 vatios, 8,5 vatios, 9,5 vatios, 13,5 vatios y 15 vatios. Supongamos que hay dos variables categóricas, el año y la potencia, y una variable numérica, que es el número de unidades vendidas en un año determinado.
colors = plt.cm.OrRd(np.linspace(0, 0.7, len(years)))
index = np.arange(len(columns)) + 0.3
bar_width = 0.7
y_offset = np.zeros(len(columns))
fig, ax = plt.subplots()
cell_text = []
n_rows = len(unitsSold)
for row in range(n_rows):
plot = plt.bar(index, unitsSold[row], bar_width, bottom=y_offset,
color=colors[row])
y_offset = y_offset + unitsSold[row]
cell_text.append(['%1.1f' % (x) for x in y_offset])
i=0
# Each iteration of this for loop, labels each bar with corresponding value for the given year
for rect in plot:
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width()/2, y_offset[i],'%d'
% int(y_offset[i]),
ha='center', va='bottom')
i = i+1
Finalmente, agreguemos la tabla al final del gráfico:
# Add a table to the bottom of the axes
the_table = plt.table(cellText=cell_text, rowLabels=years,
rowColours=colors, colLabels=columns, loc='bottom')
plt.ylabel("Units Sold")
plt.xticks([])
plt.title('Number of LED Bulb Sold/Year')
plt.show()
Polar Chart
Polar Chart es un diagrama que se traza sobre un eje polar. Sus coordenadas son ángulo y radio, a diferencia del sistema cartesiano de coordenadas x e y. A veces, también se le conoce como trama de telaraña.
El primer paso es inicializar el diagrama de araña. Esto se puede hacer configurando figure size y polar projection. Tenga en cuenta que en el conjunto de datos anterior, la lista de calificaciones contiene una entrada adicional. Esto se debe a que es una gráfica circular y necesitamos conectar el primer punto y el último punto para formar un flujo circular. Por lo tanto, copiamos la primera entrada de cada lista y la agregamos a la lista.
import numpy as np
import matplotlib.pyplot as plt
# Prepare el conjunto de datos y configure theta
theta = np.linspace(0, 2 * np.pi, len(plannedGrade))
#Inicialice el gráfico con el tamaño de la figura y la proyección polar
plt.figure(figsize = (10,6))
plt.subplot(polar=True)
# alinear las líneas de la cuadrícula con cada uno de los nombres de los sujetos
(lines,labels) = plt.thetagrids(range(0,360, int(360/len(subjects))), (subjects))
# Utilice el plt.plotmétodo para trazar el gráfico y llenar el área debajo de él
plt.plot(theta, plannedGrade)
plt.fill(theta, plannedGrade, 'b', alpha=0.2)
# trazamos las calificaciones reales obtenidas
plt.plot(theta, actualGrade)
# Añadimos una leyenda y un título bonito y comprensible a la trama y mostramos el grafico
plt.legend(labels=('Planned Grades','Actual Grades'),loc=1)
plt.title("Plan vs Actual grades by Subject")
plt.show()
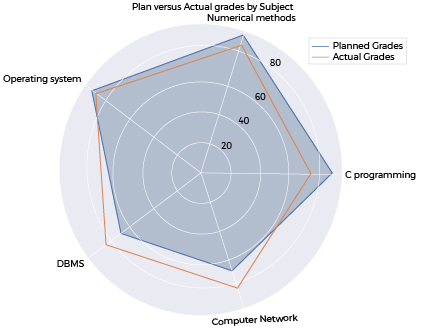
La leyenda deja claro qué línea indica las calificaciones planificadas (la línea azul en la captura de pantalla) y qué línea indica las calificaciones reales (la línea naranja en la captura de pantalla ). Esto da una indicación clara de la diferencia entre las calificaciones previstas y reales de un estudiante para el público objetivo.
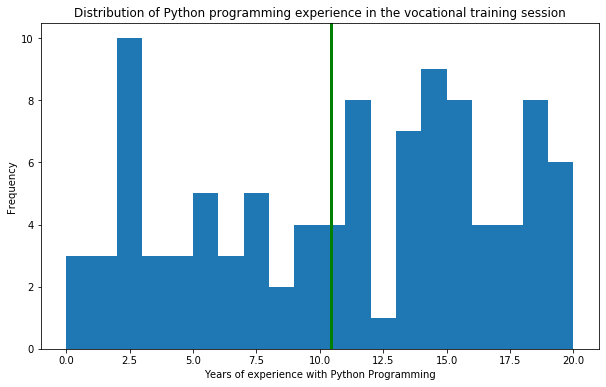
Histograma
Los gráficos de histograma se utilizan para representar la distribución de cualquier variable continua. Este tipo de gráficos son muy populares en el análisis estadístico.
Considere los siguientes casos de uso. Una encuesta creada en sesiones de formación profesional de desarrolladores contó con 100 participantes. Tenían varios años de experiencia en programación en Python, de 0 a 20. Para trazar el gráfico de histograma, ejecute los siguientes pasos:
# Trace la distribución de la experiencia del grupo:
nbins = 20
n, bins, patches = plt.hist(yearsOfExperience, bins=nbins)
# añade etiquetas a los ejes y un título:
plt.xlabel("Years of experience with Python Programming")
plt.ylabel("Frequency")
plt.title("Distribution of Python programming experience in the vocational training session")
# dibuja una línea vertical verde en el gráfico en la experiencia promedio:
plt.axvline(x=yearsOfExperience.mean(), linewidth=3, color = 'g')
# Mostrar la trama
plt.show()
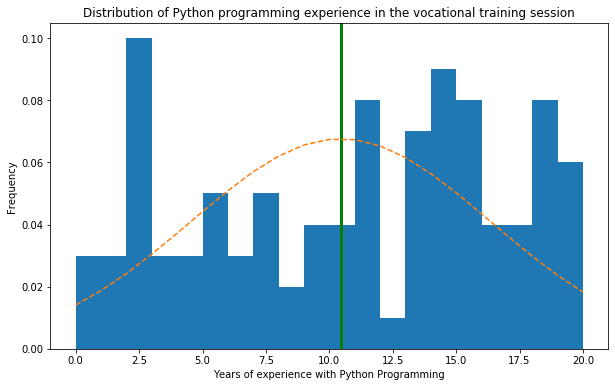
¿Podemos mejorar el gráfico para una mejor legibilidad? ¿Qué tal si intentamos trazar el porcentaje de la suma de todas las entradas en ? Además de eso, también podemos trazar una distribución normal utilizando la media y la desviación estándar de estos datos para ver el patrón de distribución.
Para trazar la distribución, podemos agregar un parámetro density=1 en la función plot.hist.
plt.figure(figsize = (10,6))
nbins = 20
n, bins, patches = plt.hist(yearsOfExperience, bins=nbins, density=1)
plt.xlabel("Years of experience with Python Programming")
plt.ylabel("Frequency")
plt.title("Distribution of Python programming experience in the vocational training session")
plt.axvline(x=yearsOfExperience.mean(), linewidth=3, color = 'g')
mu = yearsOfExperience.mean()
sigma = yearsOfExperience.std()
y = ((1 / (np.sqrt(2 * np.pi) * sigma)) * np.exp(-0.5 * (1 / sigma * (bins - mu))**2))
plt.plot(bins, y, '--')
Quizás se pregunte de dónde obtuvimos la fórmula para calcular el paso 6 en el código anterior. Bueno, aquí hay una pequeña teoría involucrada. Cuando mencionamos la distribución normal, podemos calcular la función de densidad de probabilidad usando la función de distribución gaussiana dada por
((1 / (np.sqrt(2 * np.pi) * sigma)) * np.exp(-0.5 * (1 / sigma * (bins - mu))**2))
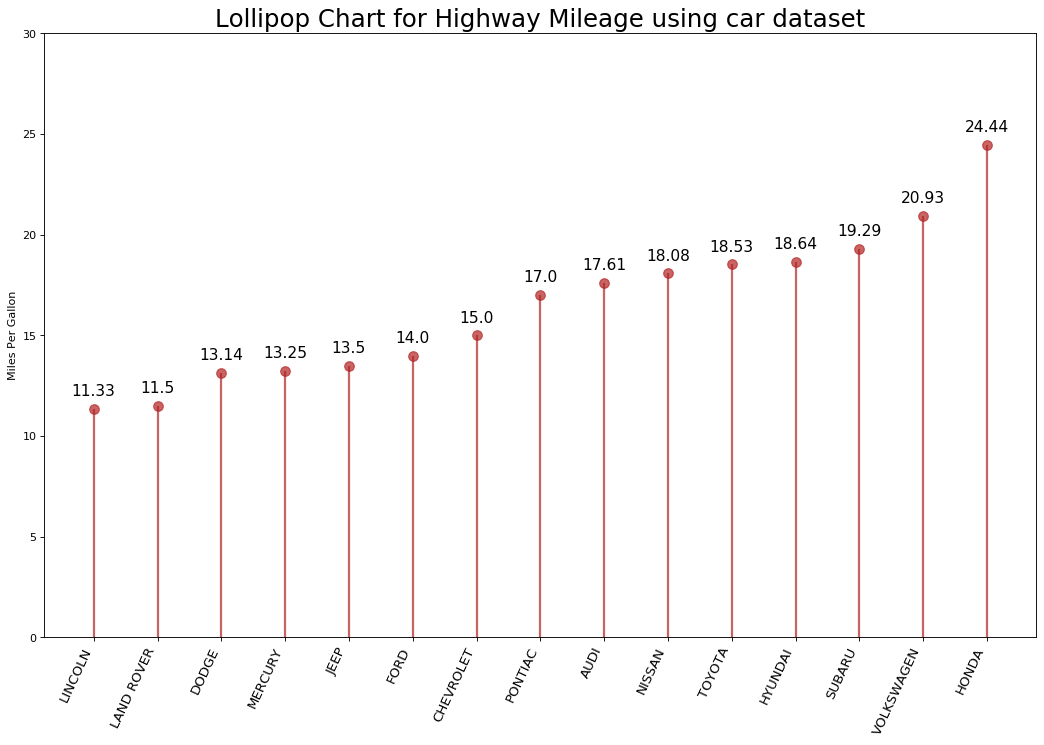
Grafico de Piruletas (Lollipop chart)
Se puede utilizar un gráfico de paleta para mostrar la clasificación de los datos. Es similar a un gráfico de barras ordenado.
#Plot the graph
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
ax.vlines(x=processedDF.index, ymin=0, ymax=processedDF.cty, color='firebrick', alpha=0.7, linewidth=2)
ax.scatter(x=processedDF.index, y=processedDF.cty, s=75, color='firebrick', alpha=0.7)
#Annotate Title
ax.set_title('Lollipop Chart for Highway Mileage using car dataset', fontdict={'size':22})
# Anotar etiquetas, xticksy ylims
ax.set_ylabel('Miles Per Gallon')
ax.set_xticks(processedDF.index)
ax.set_xticklabels(processedDF.manufacturer.str.upper(), rotation=65, fontdict={'horizontalalignment': 'right', 'size':12})
ax.set_ylim(0, 30)
#Write the values in the plot
for row in processedDF.itertuples():
ax.text(row.Index, row.cty+.5, s=round(row.cty, 2), horizontalalignment= 'center', verticalalignment='bottom', fontsize=14)
#Display the plot on the screen
plt.show()